Paper Reading: Vision Transformer
介绍
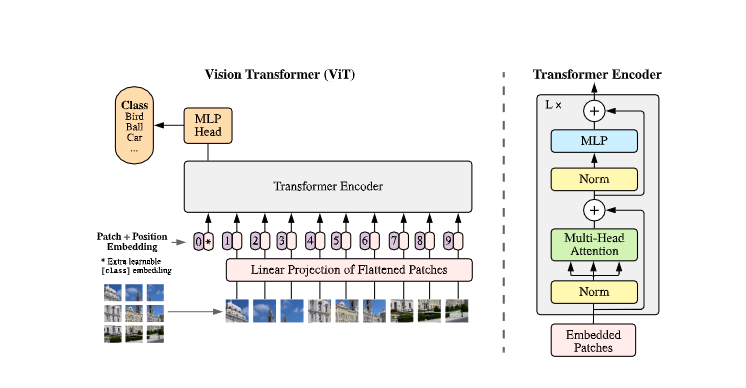
我们将图像分割为patch(与NLP中的token的处理方式相同),将所有patch的线性嵌入作为Transformer的输入。
中型数据集效果不如CNN,大型数据集(14M-300M 图像)上ViT有优势
将图像分割为固定大小的patch,对每个patch进行线性嵌入,添加位置嵌入,并将得到的向量序列送入一个标准的Transformer编码器。为了进行分类,我们使用标准的方法,在序列中加入一个额外的可学习的分类标记。
方法
Vision Transformer
为处理2D图像,将 x∈RH×W×Cx \in \mathbb{R}^{H \times W \times C}x∈RH×W×C变形为 x∈RH×(P2⋅C)x \in \mathbb{R}^{H \times (P^2 \cdot C)}x∈RH×(P2⋅C),其中(P,P)(P,P)(P,P)是每个patch的分辨率,N=HW/P2N=HW/P^2N=HW/P2是patch的数量。Transformer在其所有层中使用恒定的潜在向量大小DDD,因此我们将Patch用可训练的线性投影
z0=[xclass; ...
Paper Reading: Swin Transformer
简介
我们力图扩大Transformer的适用范围,使其能够成为计算机视觉的通用骨干。
其在语言领域的高性能转移到视觉领域的重大挑战可以用两种模式之间的差异来解释:
图片的形状是可变的,在现有的基于Transformer的模型中,token都是固定形状的。
图像中的像素分辨率比文本中的单词“分辨率”高得多。
例如语义分割这类稠密预测对于现有的Transformer模型来说是难以实现的,因为他的自注意力计算复杂度是与图像大小成平方倍增长
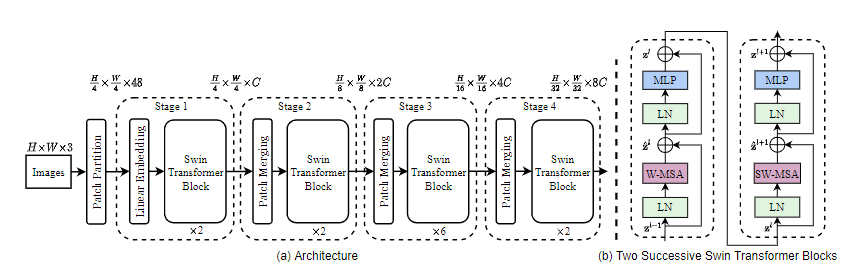
为了解决这些问题,我们提出了一种通用Transformer骨干网络,称为 Swin Transformer
如上图,其构建了层次化的特征图,可以方便地利用于密集预测的先进技术,且计算复杂度是随着图片大小线性增长,通过只在分割图像的非重叠窗口内局部计算自注意来实现的(window self-attention)。
每个窗口中的Patch数量是固定的,因此复杂度与图像大小成线性关系。
Swin Transformer的一个关键设计元素是其在连续的自注意力层中滑动分割窗口。
如下图,移位后的窗口与前一层的窗口相接,以提供它们之间的联系,大大增强了网络的 ...
Paper Reading: SENet
介绍
本文研究了网络设计的另一个方面——特征在通道之间的关系
我们提出了一个新的架构单元,称之为Squeeze-and-Excitation(SE) 块,其目的是通过明确地建模特征图通道之间的依赖关系来提高网络产生的表征的质量,利用全局信息,有选择地强调和压制特征。
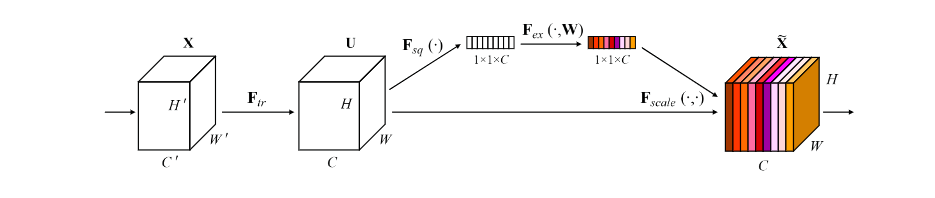
SE块的结构如下图,
FtrF_{tr}Ftr 是任意给定的变换(例如一个卷积),他将输入 XXX 映射到特征图 UUU,其中 U∈RH×W×CU \in \mathbb{R}^{H \times W \times C}U∈RH×W×C
特征图 UUU 首先经过一个名为 Squeeze 的操作,它通过在空间维度( H×WH \times WH×W )上聚合特征图来生成通道特征响应的全局分布的 Embedding,使网络的全局接收场的信息被其所有层使用。
聚合特征图后(经过 Squeeze 后),跟随一个名为 excitation 的操作,它采用一种简单的自我门控机制,将嵌入作为输入,产生一组对于每个通道的权重
这些权重最终被应用于特征图 UUU ,生成SE块的输出,随货直接输入网络的后续层。
虽然 SE 块是通用的,但 ...

Paper Reading: ResNeSt
本文提出了一个模块化的 Split-Attention 块,能够跨特征图组进行注意力操作
通过将这些 Split-Attention 块以 ResNet 方式叠加得到的一个新ResNet变体,称之为ResNeSt。
本文网络保留了整个ResNet结构,可以直接用于下游任务,而不会引入额外的计算成本。
介绍
我们研究了了ResNet的一个简单的结构性修改,在各个网络块中加入了特征图分割注意力机制。
我们的每个块都将特征图沿通道维度分为若干组和更细的子组或分块,其中每组的特征表示(输出?)是通过其分块的表示的加权组合来确定的.
我们把这样的单元称为 Split-Attention块。
通过堆叠几个 Split-Attention 块,我们创建了一个类似 ResNet 的网络,称为ResNeSt.
ResNeSt很容易被用作其他视觉任务的骨干网络,并且在多个任务上得到最先进的性能.
相关工作
现代CNN架构.
NIN首先使用全局平均池化层来代替全连接层,并采用1×1卷积层来学习特征图通道的非线性组合,这是第一种特征图注意力机制.
ResNet引入了跳层链接,缓解了深度神经网络中梯度消失的 ...

Paper Reading: Mask R-CNN
Introduction
本文提出了一个概念简单,灵活且通用的实例分割框架.扩展了Faster R-CNN,再其基础上,添加了一个用于掩码预测的掩码分支与Faster R-CNN现有的边缘框预测分支并行.
Faster R-CNN并没有设计成网络输入与输出的每个像素都对齐,主要原因是处理实例的核心操作RolRool是粗略的空间量化特征提取,为了解决像素对齐问题,本文提出了简单的,无关量化的RolAlign层.且RoIAlign对结果有很大的提升:将Mask的准确性提高了10%-50%,并且在更严格的指标下展现出更大的效益.
Mask R-CNN可以以每秒5帧的速度运行在单个GPU上,在COCO数据集上只用一台8-GPU机器训练2天
Mask R-CNN在COCO数据集的实例分割任务上比先前最先进的网络还要更好,除此之外Mask R-CNN通过极小的修改(将每个关键点看作一个单独的二元掩码)也能用在姿势关键点检测,且超过了2016年COCO关键点检测的冠军
Mask R-CNN
Faster R-CNN: Faster R-CNN包含两个阶段:
通过RPN生成候选框.
使用RoIP ...



