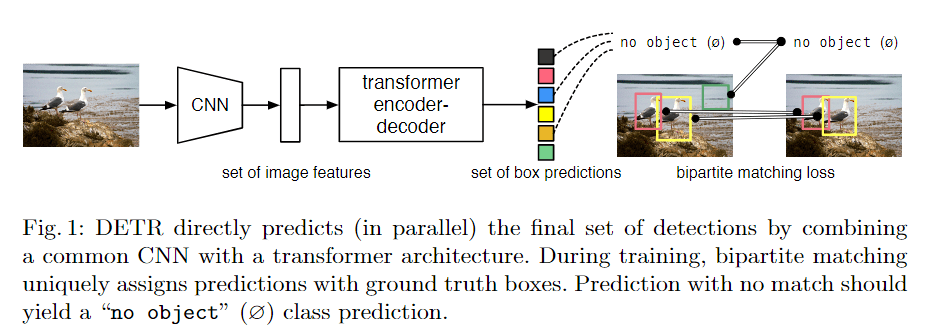
Paper Reading: Vision Transformer
介绍
我们将图像分割为patch(与NLP中的token的处理方式相同),将所有patch的线性嵌入作为Transformer的输入。
中型数据集效果不如CNN,大型数据集(14M-300M 图像)上ViT有优势

将图像分割为固定大小的
patch,对每个patch进行线性嵌入,添加位置嵌入,并将得到的向量序列送入一个标准的Transformer编码器。为了进行分类,我们使用标准的方法,在序列中加入一个额外的可学习的分类标记。
方法
Vision Transformer
为处理2D图像,将 变形为 ,其中是每个patch的分辨率,是patch的数量。Transformer在其所有层中使用恒定的潜在向量大小,因此我们将Patch用可训练的线性投影
映射到D维。 我们把这个投影的输出称为patch嵌入。
类似BERT的[class] token,我们在可嵌入的patch序列()上预置了一个可学习的嵌入embedding向量,该序列在Transformer编码器的输出( )输出端的状态作为图像表示y。
在预训练和微调期间,一个分类头被连接到。分类头由一个具有隐藏层的MLP实现,在微调时由一个单一的线性层实现。
位置嵌入被添加到patch嵌入中以保留位置信息。 使用标准的可学习的一维位置嵌入,因为没有观察到使用更先进的二维感知位置嵌入的明显性能提升。
Transformer编码器由多头自注意力(MSA)和MLP块的交替层组成。
Layernorm(LN)在每个块之前被应用,每个块之后都有残差连接
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Toby的小博客!
相关推荐


评论



