Paper Reading: An Image is Worth One Word
通过自然语言指导创作,Text-to-Image达到了极高的创作自由度,但是仍然难以通过语言指导生成特定概念的图像,修改它们的外观,或将他们组成新的角色和新的场景。
本文提出了一种允许这种创作的简单方法:
- 使用给定的3-5张图像,学习在冻结的
Text-to-Image的嵌入空间中通过新的“单词”描述它。 - 这些“单词”可以组合成自然语言句子,指导个性化创作。
我们发现,单个单词足以捕获多样的概念。
主要贡献:
- 介绍了个性化的文本到图像生成任务,在自然语言指导下合成了用户提供的概念的新颖场景。
- 提出
文本反转想法,目标是在文本编码器的嵌入空间中寻找新的伪词,这些伪词可以捕捉到高级语义和精细的视觉细节。
介绍
最近的大规模Text-to-Image模型展现出了对自然语言描述进行推理的前所未有的能力。允许用户用从未见过的构图合成新奇的场景,以无数种风格产生生动图片。然而,它们的使用受制于用户通过文本描述所需目标的能力。
在大规模的模型中引入新的概念往往非常困难。重新训练模型非常昂贵,对少数例子进行微调通常会导致灾难性的遗忘。更多的方法是冻结了模型并训练变换模块以在面对新的概念时调整输出。
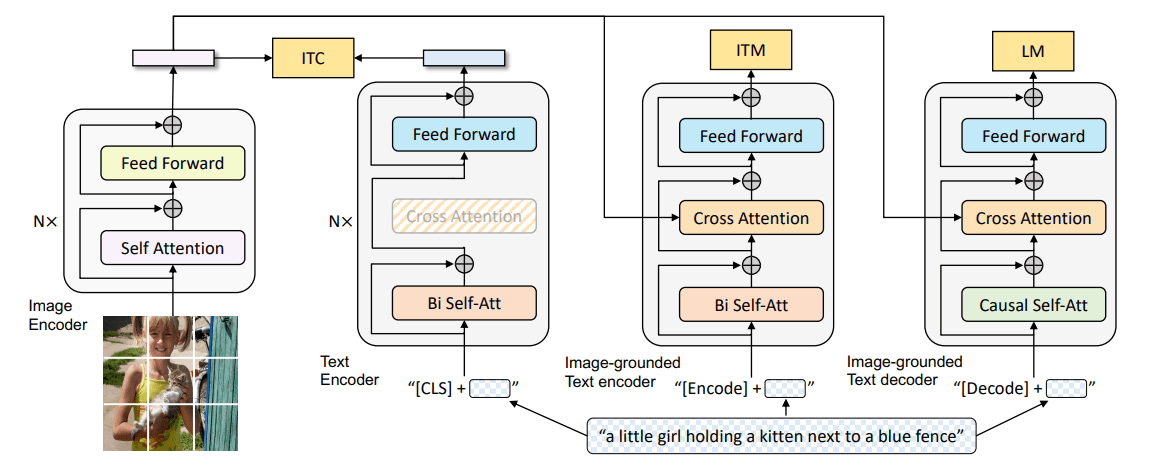
本文提出通过与训练好的文本到图像的文本嵌入中寻找新词来克服这些困难。在文本编码器过程的第一阶段(每个token替换成自己的嵌入向量),找到新的嵌入向量,代表新的、特定的概念。
我们用一伪词(用 表示)表示一个新的嵌入向量。这个伪词被作为任何其他词来对待,例如人们可以询问模型“a photograph of on the beach”,甚至组合两个概念“a drawing of in the style of ”
为了找到这些伪词,我们在一个冻结的Image-to-Text模型和一个描述该概念的小型图像集,找到一个单一的词嵌入使 “A photo of ”这样的句子导致从我们的小型图像集中重建图像。 这个嵌入是通过一个优化过程找到的,我们称之为“文本反转”。

方法
我们的目标是使语言指导下的生成新的用户指定的概念。为了做到这一点,我们将这些概念编码到一个预先训练好的Text-to-Image模型的中间表示中,理想情况下,这样做的方式允许我们利用这种模型所代表的丰富语义和视觉先验,并利用它指导概念的直观视觉转换。
Latent Diffusion Models
我们在Latent Diffusion Models(LDMs)上实现我们的方法,(LDM)是最近引入的一类Denoising Diffusion Probabilistic Models(DDPMs),在自编码器的潜在空间中操作。
文本编码器
在我们的工作中,指定一个占位符字符串,,代表我们希望学习的新概念。嵌入过程中进行干预,用一个新的、学到的嵌入 替换与tokenized字符串相关的向量,将概念“注入”我们的词汇中。这样一来,我们就可以像对待其他词一样,组成包含该概念的新句子。
文本反转
为了找到这些新的嵌入,我们使用一个小的图像集(3-5张),这些图像在不同的背景或姿势等多种情况下描述了我们的目标概念。我们通过直接优化LDM损失找到 。
优化目标定义为:
保持 和 固定,即冻结Text-to-Image模型。这是一个重建任务。因此,我们希望它能促使学习到的嵌入捕捉到概念特有的精细视觉细节。