Paper Reading: ImageBERT
由人类手动编写的图像描述是高质量的,但十分昂贵。为了利用互联网上有无数的网页相关的图像。本文设计了一种弱监督的方法收集来自网络的大规模图文对数据。由此产生的数据集LAIT(Large-scale weAk-supervised Image-Text)包含1000万张图片以及平均长度为13个单词的描述。我们将在实验中表明,LAIT对视觉语言预训练是有益的。
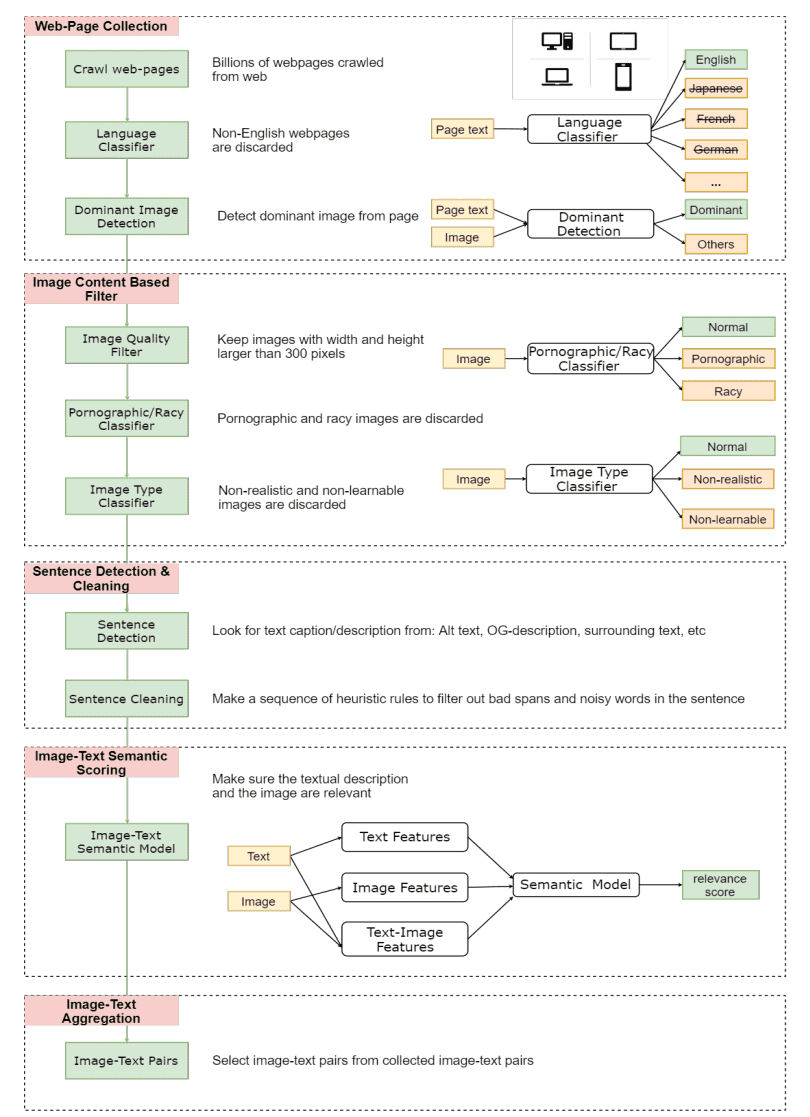
方法
从网络上抓取数十亿的网页
Web-page Collection:
- 丢弃非英语的网页
- 我们解析每个网页收集图像URL
- 通过HTML标签和DOM树的特征检测主导图像。
- 非主导图像被丢弃
Image Content Based Filtering:
- 只保留宽度和高度都大于300像素的图片。
- 过滤不和谐图片。
- 应用二元分类器来丢弃不自然的、不真实的和不可读的图像。
Sentence Detection & Cleaning:
使用以下数据源作为图片的文本描述:
- HTML中用户定义的元数据,如Alt或Title属性,
- 图片的周围文本等;
- 我们制定了一系列启发式规则
- 过滤掉句子中的不良跨度和噪声词(垃圾邮件/色情),并将句子保持在正常长度内。
- 摒弃那些有高频的句子。
Image-Text Semantic Scoring
我们要确保文本和图像在语义上是相关的。通过小规模的监督图像-文本数据,训练一个弱图像-文本语义模型来预测相关性。以过滤掉不相关的对。
Image-Text Aggregation.
一张图片从多个网页上下载,因此有不同的文字描述。在这种情况下,我们只选择得分最高的<文本,图像>对。如果有太多的图像具有相同的描述,我们将直接从语料库中删除所有这些对。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Toby的小博客!
相关推荐


评论


