Paper Reading: METER
最近的工作表明,完全基于Transformer的模型比OD-RFs的模型更有效。但它们在下游任务上的表现往往会明显下降。
本文提出METER,一个多模态的端到端Transformer框架。
沿着多个维度剖析了模型设计:视觉编码器、文本编码器、多模态融合模块、架构设计,以及预训练目标。
介绍
视觉Transformer(ViTs)在视觉特征提取方面显示出巨大的潜力。因此,本文使用ViTs作为图像编码器训练一个完全基于Transformer的VLP模型。
最近试图采用视觉Transformer仍然弱于最先进的OD-RFs模型。为了缩小性能差距,我们提出了METER,一个多模态的端到端Transformer框架,通过它我们彻底研究了如何以端到端方式设计和预训练一个完全基于Transformer的VLP模型。
我们沿着多个维度对模型设计进行剖析
- 视觉编码器,如
CLIP-ViT、Swin Transformer - 文本编码器,如
RoBERTa、DeBERTa - 多模态融合模块,如合并注意力(
merged attention)、共同注意力(co-attention) - 架构设计,仅编码器与编码器-解码器
- 预训练目标,例如遮蔽图像建模。
我们通过在四个常用的图像标题数据集上对METER下的模型预训练来进行研究。在视觉问题回答、视觉推理、图像文本检索和视觉关联任务中对它们进行了测试,总结如下:
ViT在VLP中比语言Transformer起着更重要的作用,Transformer在单模态任务上的表现并不能说明其在VL任务上的表现。- 交叉注意的加入有利于多模态融合,这比单独使用自我注意能带来更好的下游性能。
- 在
VQA和0-shot图像-文本检索任务中,仅编码器的VLP模型比编码器-解码器模型表现得更好。 - 在我们的设置中,增加遮蔽图像建模损失不会改善下游任务的表现。
方法

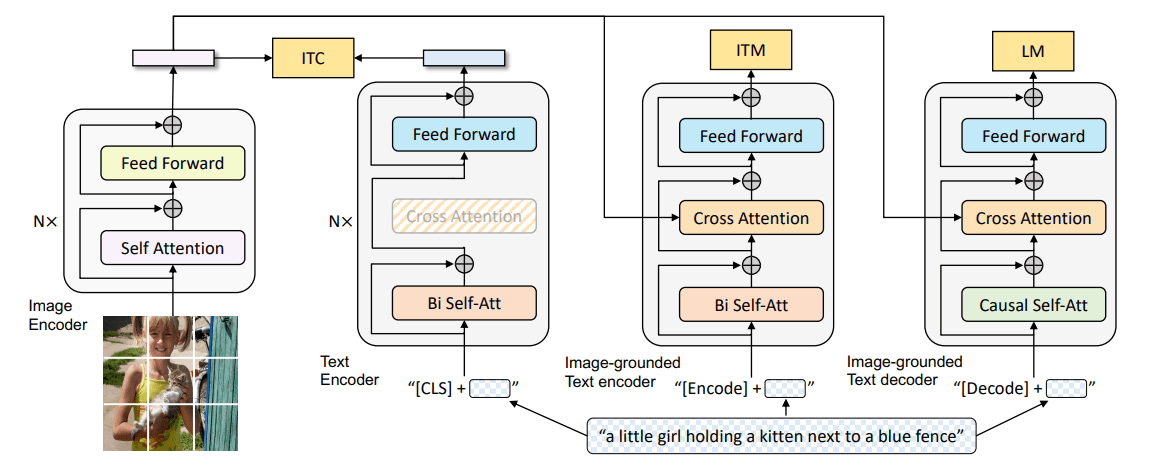
给定一个图文对,首先通过一个文本编码器与一个视觉编码器提取文本特征 和视觉特征 ,然后将文本和视觉特征馈送到多模态融合模块以产生跨模态表示,在生成最终输出之前选择性地将其馈送到一个解码器。
模型架构
视觉编码器
首先将图像分割成补丁,然后将补丁馈送到转换器模型中。最近基于ViT的VLP模型与最先进的基于区域特征的模型(如VinVL)相比,效果仍然较差。本文比较了原始ViT、DeiT、Distilled-DeiT、CaiT、VOLO、BEiT,Swin Transformer和CLIP-ViT。
文本编码器
首先将输入句子分割成子词序列,然后在句子的开头和结尾插入两个特殊标记以生成输入文本序列。获得文本嵌入后,现有工作有两种处理方式:
- 直接馈送到多模态融合模块,融合模块通常使用
BERT进行初始化,单个BERT融合模块需要同时编码文本和进行多模态融合。 - 在融合之前馈送到几个文本特定的层,也是本文选择的方法,分解为两个模块,将特征馈送到融合模块之前经过文本编码器。
在这项工作中,我们研究了使用BERT,RoBERTa,ELECTRA,ALBERT和DeBERTa进行文本编码。此外,还尝试仅使用一个简单的词嵌入查找层,该层使用BERT嵌入层初始化。
模态融合

研究了两种类型的融合模块:
- 合并注意力(
merged attention),文本和视觉特征简单地拼接在一起,馈送到单个Transformer块中 - 共同注意力(
co-attention),文本和视觉特征独立地馈送到不同的Transformer块中,使用交叉注意等来实现交叉模态交互。
合并注意力和共同注意模型可以实现相仿的性能。然而,合并注意力效率更高,因为两种模态使用同一个Transformer模块。
仅编码器与编码器-解码1器
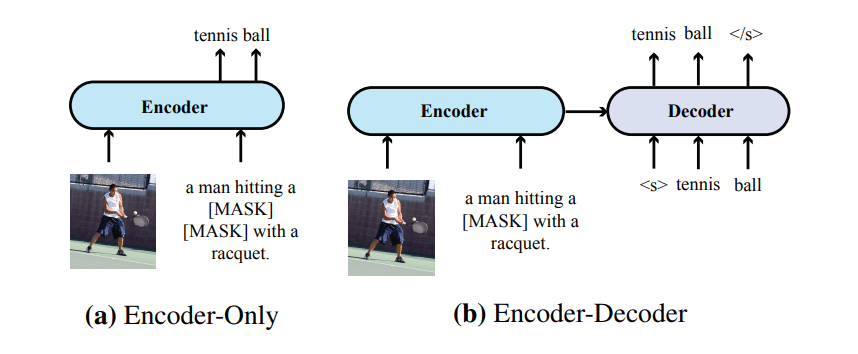
- 仅编码器架构跨模态表示直接馈送到输出层以生成最终输出。
- 编码器-解码器架构跨模态表示首先馈送到解码器,然后馈送到输出层。解码器同时关注编码器表示和先前生成的
token,自回归的生成输出。
预训练目标
Masked Language Modeling.
Image-Text Matching.
Masked Image Modeling.
给定一些列视觉特征 随机屏蔽一些视觉特征,模型在给定其余视觉特征和未掩码标记 的情况下重建视觉特征 ,最小化MSE损失。
为了研究MIM对VLP的有效性,我们将图像遮罩重建视为一项patch遮罩分类任务,并提出了两种实现该想法的方法。
Masked Patch Classification with In-batch Negatives
模仿MLM,提出让模型通过使用动态构建的词汇表构建batch内负样本来重建输入patch。
在每个训练步骤对一个batch中所有图文对进行采样,将batch中所有图片中的patch视为候选patch,屏蔽的输入patch,模型需要从候选集中选择正确的patch。
Masked Patch Classification with Discrete Code.
获取输入patch的离散表示,训练模型重建离散的token。使用VQ-VAE模型将每个图像token化为一系列离散token。调整每个图片大小使patch数量等于token数量。然后随机屏蔽 的patch,让模型预测离散的token。
METER默认设置
- 预训练目标,除非另行说明,仅使用语言屏蔽建模(
MLM)和图像文本匹配(ITM)。 - 预训练数据集,在四个常用数据集上预训练模型,COCO、 Conceptual Captions、 SBU Captions 和 Visual Genome。
- 下游任务,主要关注VQAv2,也在Flickr30k进行
0-shot测试。
实验
编码器
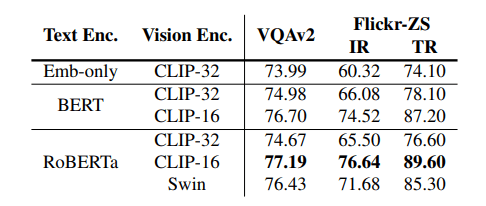
图像分辨率
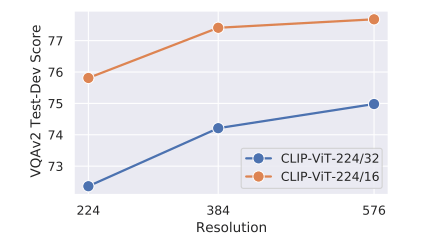
在微调过程中提高图像分辨率可大大提高 VQAv2上的性能
共同注意力与合并注意力

共同注意力的表现优于合并注意力,添加解码器对于我们的判别性VL任务没有帮助
预训练目标

语言遮罩建模 (MLM) 和图像文本匹配 (ITM)可以提高模型性能,但图像遮罩建模(MIM)目标都会导致下游任务的性能下降。
性能

与预训练有 图像的模型在视觉问答、视觉推理、视觉蕴涵以及0-shot图像检索和文本检索任务方面的比较。

与Flickr30k上使用 图像进行预训练的模型以及微调设置中的COCO图像检索和文本检索任务的比较。