Paper Reading: VLP 综述
本文调查了视觉语言预训练(VLP)的最新进展和新领域,包括图像-文本和视频-文本预训练。
Feature Extraction 特征提取
如何对图像、视频和文本进行预处理和表示,以获得对应的特征
图像
(1) 基于目标检测的区域特征(OD-RFs)
利用预训练好的目标检测器(最常用的是带有自下而上注意力的Faster R-CNN)来提取视觉特征。
将OD输出的 -d 区域特征嵌入,以及对边界框和空间位置(边缘框左上角坐标、右下角坐标、图像大小占比)嵌入到高维 -d的视觉几何嵌入,两者相加作为基于目标检测的区域特征(OD-RFs)。
提取区域特征很费时,为了缓解这个问题,区域特征通常被预先抽取存储在磁盘上,而OD则在训练期间被冻结,但也带来了负面影响(限制了VLP模型的容量,受限于OD训练时的固定词汇等)
e.g. VIsualBERT ViLBERT
(2) 基于CNN的网格特征(CNN-GFs)
利用卷积神经网络(CNN)得到网格特征。
- 通过直接使用网格特征作为视觉特征来对
CNN进行端到端的训练。 - 也可以先用学习到的视觉字典离散网格特征,然后将其输入跨模式模块。
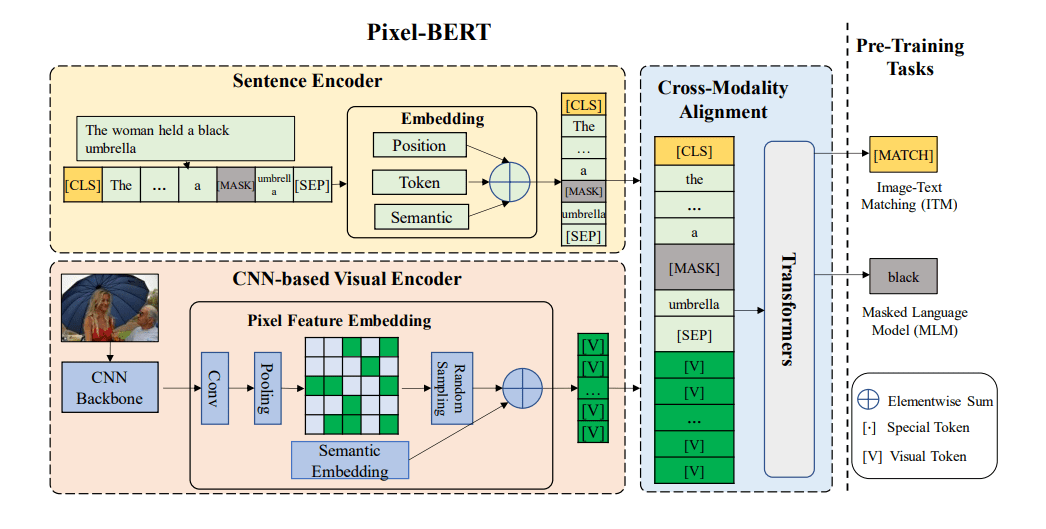
e.g. Pixel-BERT CLIP-ViL
(3) 基于ViT的patch特征(ViT-PFs)
即如同ViT一样吗,将图像分割为不重叠的个patch,作为Transformer的输入。
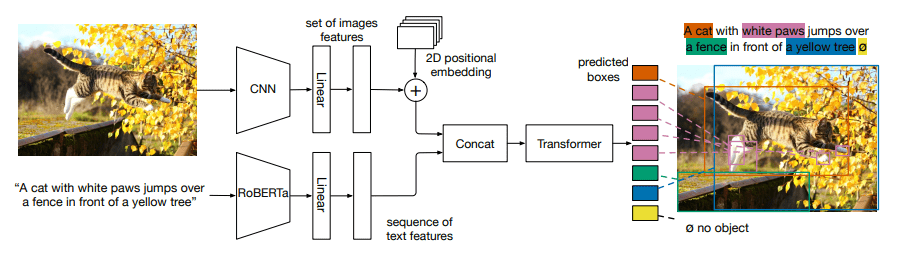
e.g. MDETR ViLT
视频
帧的视频片段,通过上述图像特征(通常是CNN-GFs和ViT-PFs)提取方法组帧提取特征。
- 对于
CNN-GFs,使用预训练过(在ImageNet上的ResNet,Kinetics上的SlowFast等)的模型来提取每个视频帧的2D和3D特征,作为视觉特征串联起来,通过FC层投影到与标记嵌入相同的低维空间。 - 对于
ViT-PFs,分辨率为 视屏片段,被划分为 个大小为 的非重叠时空patch,其中 。
文本特征提取
遵循BERT等语言模型的预处理方式,插入开始标记与结束标记。最后将词嵌入与位置嵌入和文本类型嵌入相加。
模型架构
从两个不同的角度介绍VLP模型的架构:
- 从多模态融合的角度来看单流与双流,
- 从整体架构设计角度看仅编码器与编码器解码器。
单流与双流
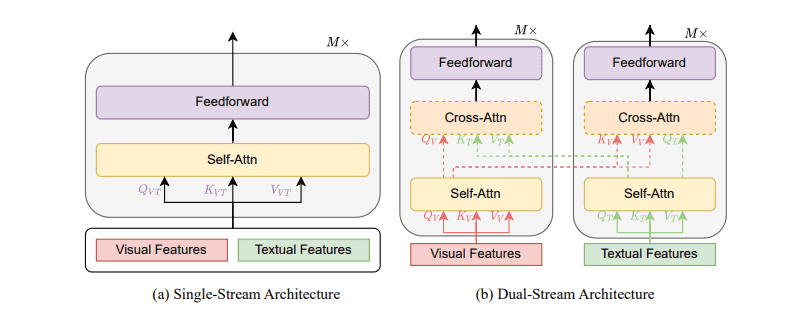
单流
单流架构通常将文本和视觉特征拼接在一起,输入单个Transformer模块。通常情况下单流架构参数量更少。
e.g. VisualBERT PixelBERT ViLT
双流
双流架构两个模态都独立使用不同的Transformer模块,并使用交叉注意力(cross-attention)实现跨模态交互(为更高效率,也可以没有交叉注意力)。
e.g. ViLBERT ALIGN METER
仅编码器与编码器解码器
仅编码器架构将跨模态表示直接馈送到输出层以生成最终输出。
编码器解码器架构将跨模态表示首先馈送到解码器,然后馈送到输出层。
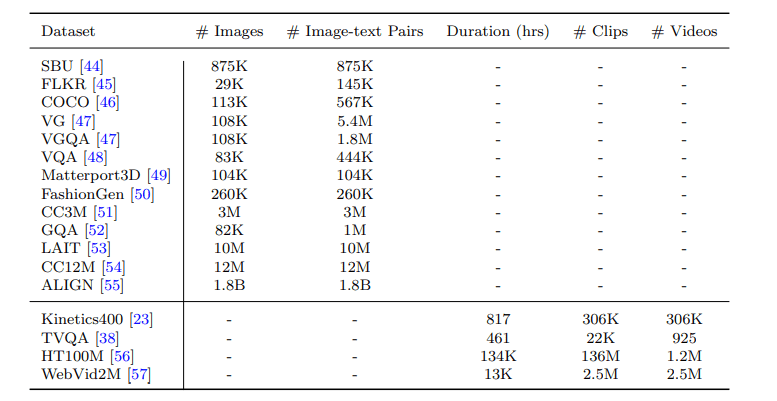
VLP 数据集
预训练目标
我们将训练前目标分为四类:
- 完成利用可见的信息来重建被掩蔽的元素。
- 匹配对齐视觉特征和文本特征空间,以生成通用的视觉语言表示。
- 时序是通过对中断的输入序列重新排序来学习良好的表示,主要针对视频相关的预训练。
- 特定类型由其他训练前对象组成,例如视觉问答和视觉字幕
语言遮罩建模(MLM)
遵循BERT的VLP模型以 的概率随机屏蔽每个文本输入token,并通过在 的时间内使用特殊token“[MASK]” 替换被屏蔽的token,在 的时间内使用随机文本令牌,在 的时间内使用原始令牌来执行屏蔽。正式定义如下:
其中 表示视觉, 表示文本标记, 表示屏蔽的文本标记, 表示剩余的文本标记, 表示训练数据集。
前缀语言建模(PrefixLM)
是 MLM 和语言建模(LM)的统一。使模型具有实体生成能力,使得文本诱导的无需微调的zero-shot泛化性。前缀语言建模不同于标注的语言建模,其允许对前缀序列进行双向关注。seq2seq框架下的PrefixLM不仅像MLM中那样享受双向上下文表示,还可以执行类似于LM的文本生成。正式定义如下
其中 表示前缀序列的长度。
视觉遮罩建模(MVM)
通常以 的概率遮蔽视觉区域或patch,根据剩余的视觉特征和文本特征重建。被掩盖的视觉特征被设置为零。由于视觉特征是高维和连续的,VLP模型为MVM提出了两个变种。
特征遮罩回归
回归到其原始视觉特征。将被掩盖特征的模型输出转换为与原始视觉特征相同维度的向量,并在原始视觉特征和向量之间应用L2回归。其正式定义如下。
其中 表示预测的视觉表示, 表示原始视觉表示。
屏蔽特征分类
学习预测被掩盖的特征的对象语义类别。将遮蔽特征的输出送入FC层与softmax函数输出预测的归一化分布。但是这里没有ground truth,有两种方法来训练:
- 将
OD中最有可能的物体类别作为ground-truth硬标签,应用交叉熵损失来最小化预测和伪类之间的差距。 - 利用软标签作为监督信号,即原始输出(即对象类别的分布),并使两个分布之间的
KL散度最小。
正式定义为:
对于硬标签:
对于软标签
其中 为检测到的被检测物体类别, 为类别分布,表示视觉区域的数量。
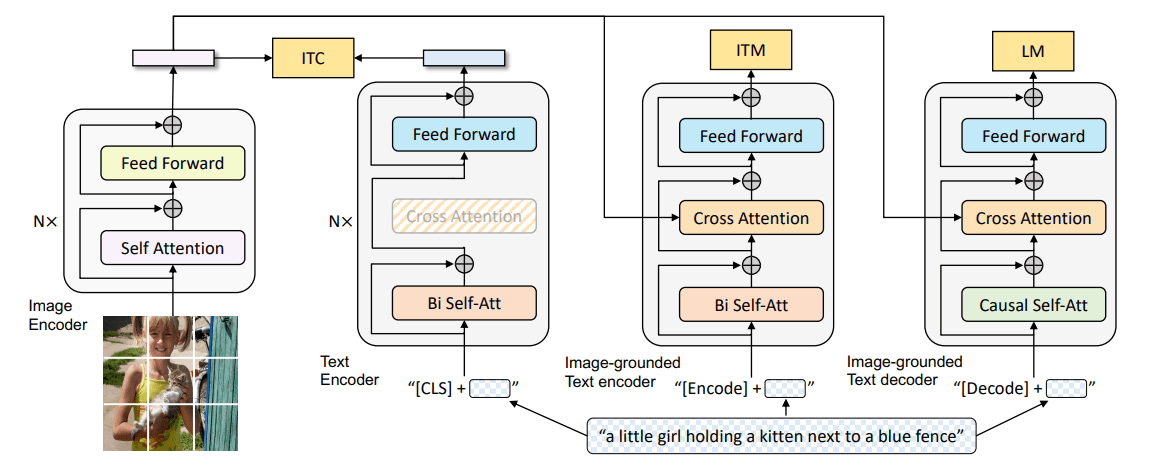
视觉-语言匹配
旨在将视觉和语言投射到同一特征空间。
- 单流
VLP模型中,使用特殊标记“[CLS]”的对应输出表示作为两种模式的融合表示。 - 双流
VLP模型中,将特殊视觉标记的视觉表示“[CLSV]”和特殊文本标记的文本表示“[CLST]”串联起来,作为两种模式的融合表示。
将两种模式的融合表示送入FC层和一个sigmoid函数预测是否匹配(0到1之间,0表示不匹配,1表示匹配)。在训练过程中,VLP模型在每一步都会从数据集中抽出正面或负面(从其他样本中随机选取的视觉或文字替换成对的样本)的配对。
视觉-语言对比性学习
在解码器输出的对象的嵌入表示和交叉编码器输出的文本表示之间强制对齐。使视觉和语言的特征空间更相似。
视觉语言对比学习(VLC)从 个可能的视觉语言对中预测出匹配的视觉语言对。在一个batch中,有 个负样本对。使用特殊视觉标记的视觉表示[CLSV]和特殊文本标记的文本表示[CLST],分别表示视觉和语言的聚合表示。 计算softmax归一化的视觉-文本相似度和文本-视觉相似度,并利用视觉-文本和文本-视觉相似度的交叉熵损失来更新。相似性通常由点积实现。正式的定义如下。
其中 表示相似度函数, 表示温度系数。 和 表示视觉到文本检索和文本到视觉检索的标签。
单词-区域对齐(WRA)
无监督的预训练目标,对齐视觉区域(视觉patch)和词语,利用最优传输来学习视觉和语言之间的对齐。
帧序建模(FOM)
为了更好地模拟视频的时间,随机打乱一些输入帧的顺序,然后预测每个帧的实际位置。
特定预训练目标
为了更好地适应下游任务,VLP模型有时会使用一些下游任务的训练对象,如视觉问题回答(VQA),以及视觉字幕(VC),作为预训练目标。
下游任务
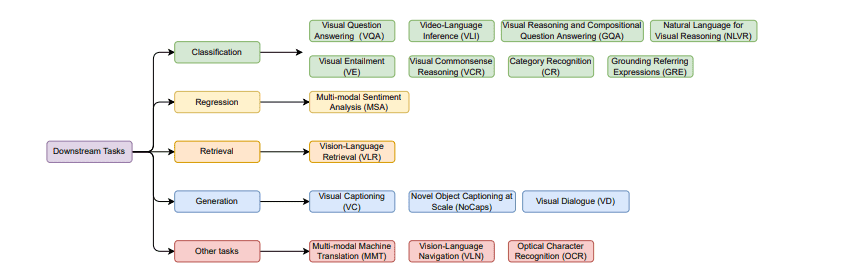
视觉问题回答(Visual Question Answering,VQA)
给予一个视觉输入,让模型从一个选项池中预测出最佳答案。
视觉推理和组合问答(Visual Reasoning and Compositional Question Answering,GQA)
是VQA的升级版,GQA包括多维度的评价指标:一致性、有效性、合理性、分布性和接地性。
视频语言推理 (Video-Language Inference,VLI)
给定一个带有对齐字幕的视频片段,配上基于视频内容的自然语言假设,一个模型需要推断出该假设是否被给定的视频片段所包含或矛盾。
视觉蕴含 (Visual Entailment,VE)
图像是前提,文本是假设。预测文本是否为“蕴涵图像”。有三个标签:蕴含、中立和矛盾。
视觉常识推理(Visual Commonsense Reasoning,VCR)
以多项选择题的形式存在。对于提出的关于图像的问题,有几个备选答案。模型必须从几个答案中选择一个答案,然后从几个备选理由中选择选择这个答案的理由。
接地引用表达式(Grounding Referring Expressions,GRE)
旨在通过引用表达式在图像中定位某些区域。
类别识别(Category Recognition,CR)
识别产品的类别和子类别。
视觉语言检索(Vision-Language Retrieval,VLR)
通过适当的匹配策略来理解视觉和语言。即从大的描述池中获取最相关的对应描述(语言检索图片或图片检索语言)。
视觉字幕(Visual Captioning,VC)
旨在为给定的视觉输入生成语义和语法上适当的文本描述。
视觉对话(Visual Dialogue,VD)
给定一个图像,一个由一系列问答对组成的对话历史记录,以及一个自然语言后续问题,该任务的目标是以自由形式的自然语言回答问题(例如,生成答案)。
多模态机器翻译 (Multi-modal Machine Translation,MMT)
翻译和文本生成的双重任务,将文本从一种语言翻译成另一种语言,并带有来自其他形式(例如图像)的附加信息。
视觉语言导航(Vision-Language Navigation,VLN)
是代理运动的基础语言任务,因为它看到并探索了基于语言指令的现实世界动态。被视为序列到序列转码的任务,通常具有较长的序列,且是一个实时演变的任务。
光学字符识别(Optical Character Recognition,OCR)
一般是指从图像以及文件中提取手写或打印的文本,它包括两部分:文本检测(类似于回归)和文本识别(类似于分类)。
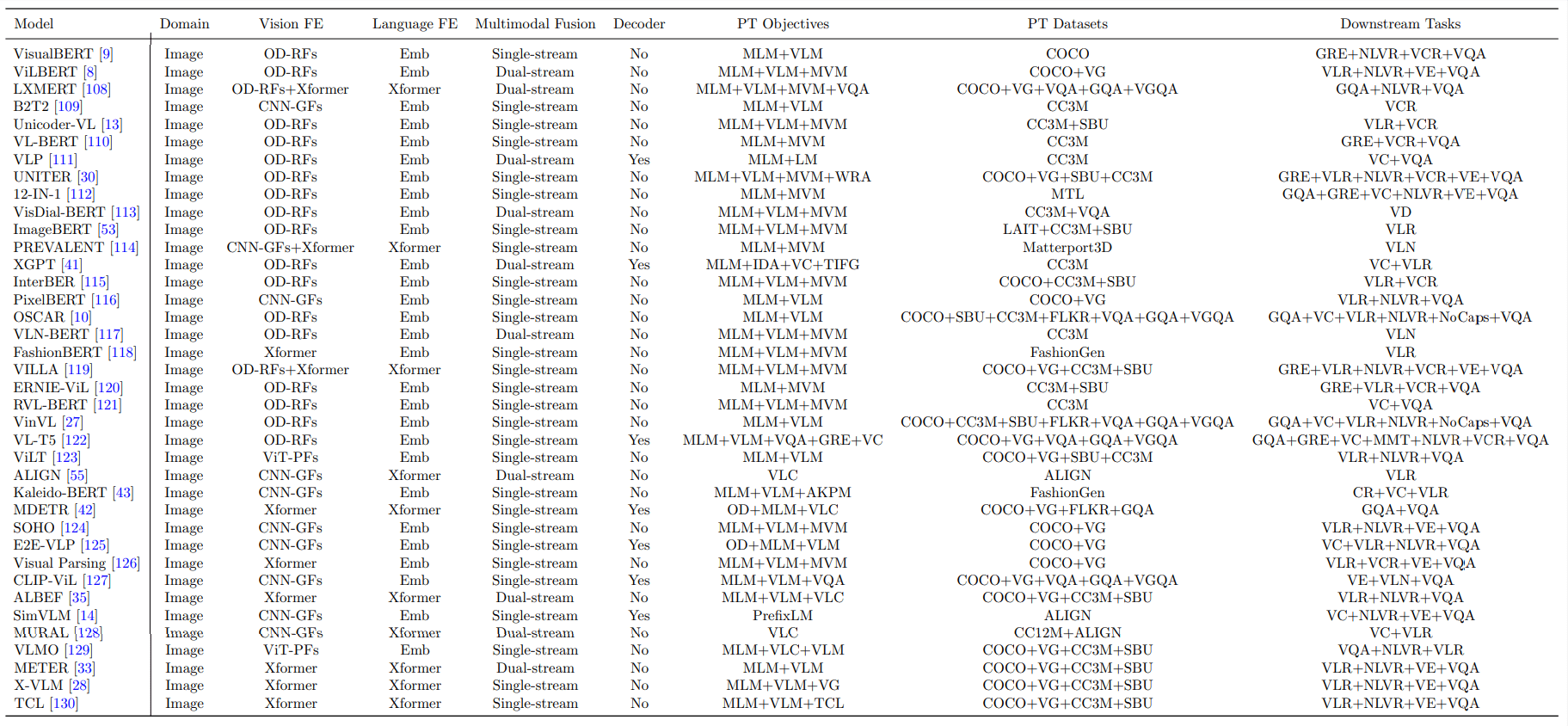
SOTA VLP 模型
下游任务的数量决定了该模型是通用的还是特定领域的VLP。FE:特征提取。PT:预训练。Emb:嵌入。数据集栏中的SC:自我构建或自我收集的。数据集栏中的MTL:相应工作中的所有多任务学习的数据集