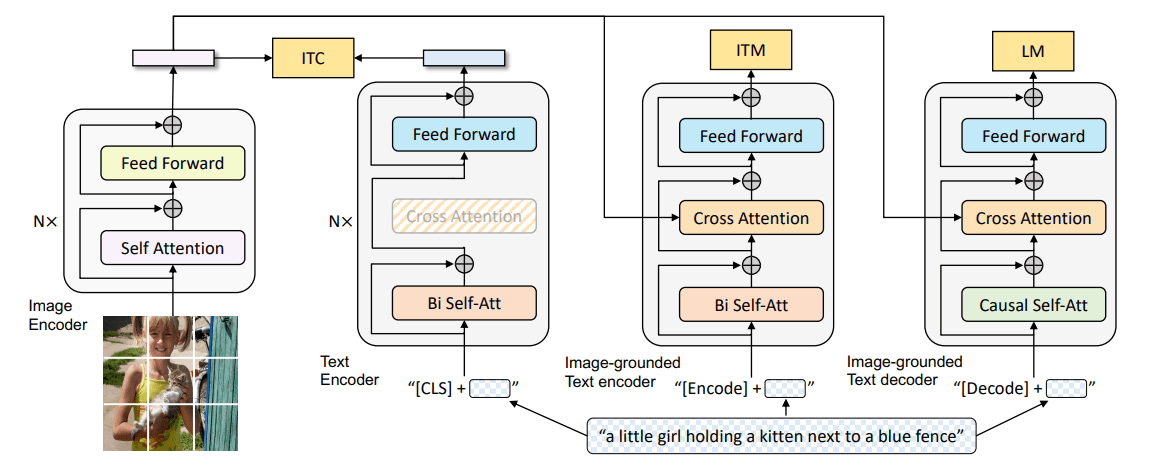
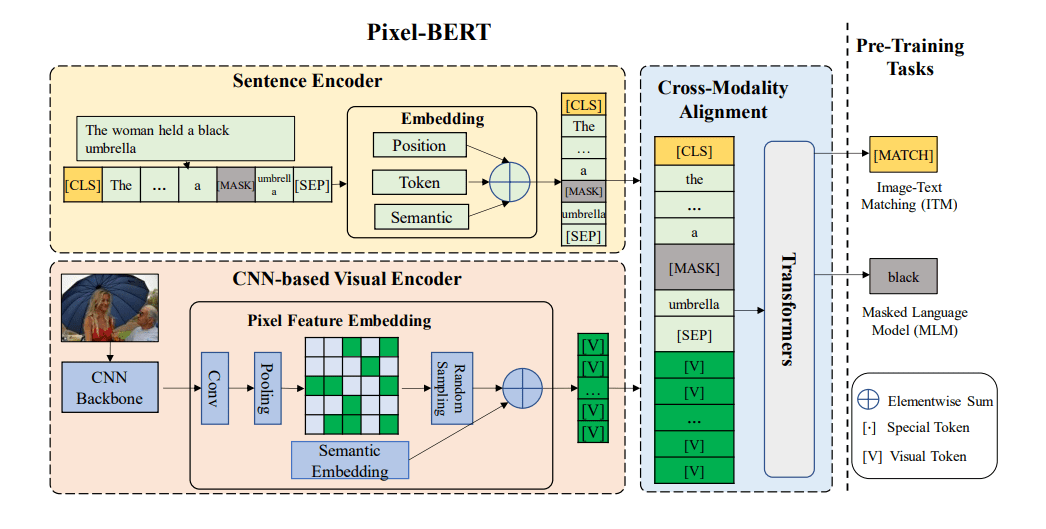
Paper Reading: CLIP-ViL
在大量从网络获取的图文对上训练的CLIP在下游任务上表现出了强大的0-shot能力。为了挖掘CLIP在V&L任务所带来的优势,本文提出在两个场景使用CLIP作为视觉编码器:
- 插入
CLIP到特定任务微调。 - 将
CLIP与V&L模型共同训练。
Introduction
最近的工作观测到视觉表示成为为V&L模型的性能瓶颈,学习强大视觉编码器对于V&L模型是至关重要的。
但是现在广泛使用的视觉编码器使用手动标注的数据集训练,标注成本高,且视觉表征能力受到预先定义的类别标签的限制。所以,需要一种不受固定标签集限制,对未见过的物体和概念具有概括能力的视觉编码器,能够在大规模数据集上预训练。
最近CLIP被提出用来基于语言监督学习视觉概念。它是在从互联网上抓取的4亿个噪声图像文本对上训练的,并需要很少的人类注释。且有强大的0-shot能力。然而,直接将CLIP作为0-shot模型应用于V&L任务被证明是困难的,因为许多V&L任务需要复杂的多模式推理。
本文首次对使用CLIP作为V&L任务的视觉编码器的大规模实证研究->
- 将
CLIP插入到直接的特定任务的微调中,将其称为CLIP-ViL,在视觉问题回答,图像字幕,以及视觉和语言导航带来了可观的改进。 - 将
CLIP与图像文本对的V&L预训练相结合,并转移到下游任务,称为CLIP-ViLp,在三个基准上表现异常出色,包括VQA、SNLI-VE和GQA在VQA创造新的SOTA。
实验结果
CLIP-ViL
VQAv2.0
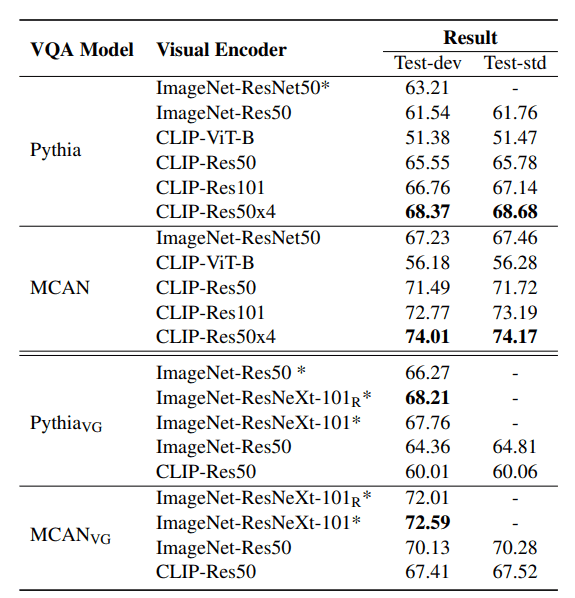
上面部分为与在ImageNet分类任务上预训练的视觉特征提取器相比。下面为对Visual-Genome(VG)进行进一步检测预训练后的结果。
*标志着来自(Jiang等人,2020)的结果。R表示区域特征,而其他方法使用网格特征。
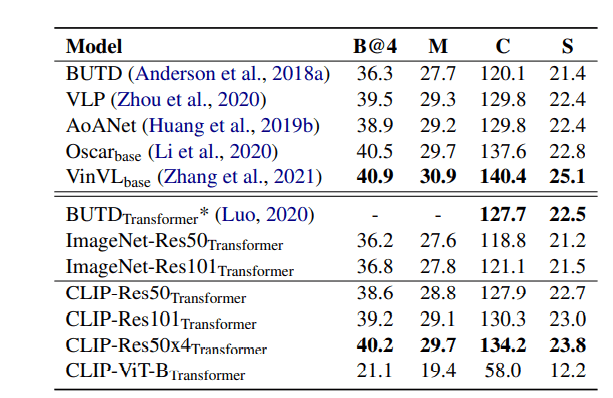
Image Captioning
Vision-and-Language Navigatio(R2R)
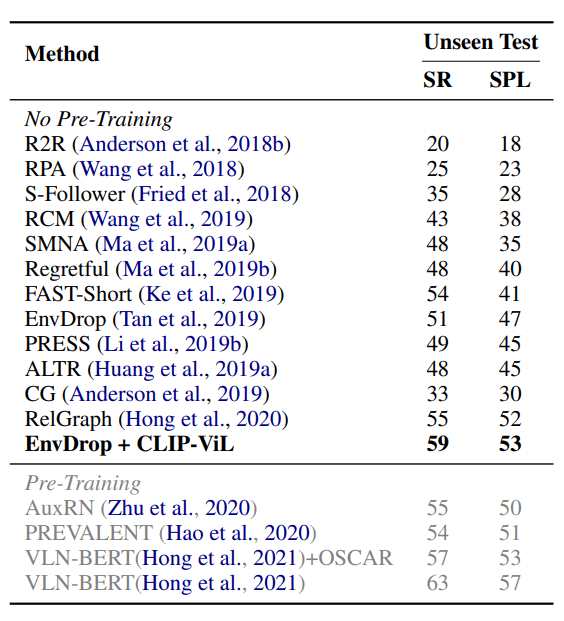
R2R数据集的不可见的测试结果。SR和SPL是成功率和按路径长度归一化的成功率。预训练方法主要是在Matterport3D环境中进行域内预训练。
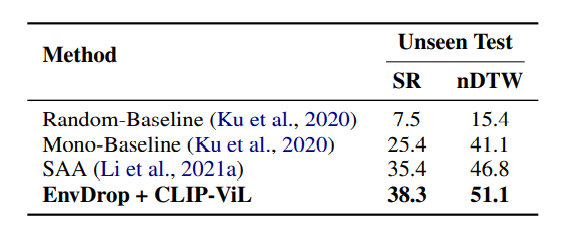
单语设置下的RxR数据集的不可见测试结果。SR和nDTW是指成功率和归一化动态时间扭曲。
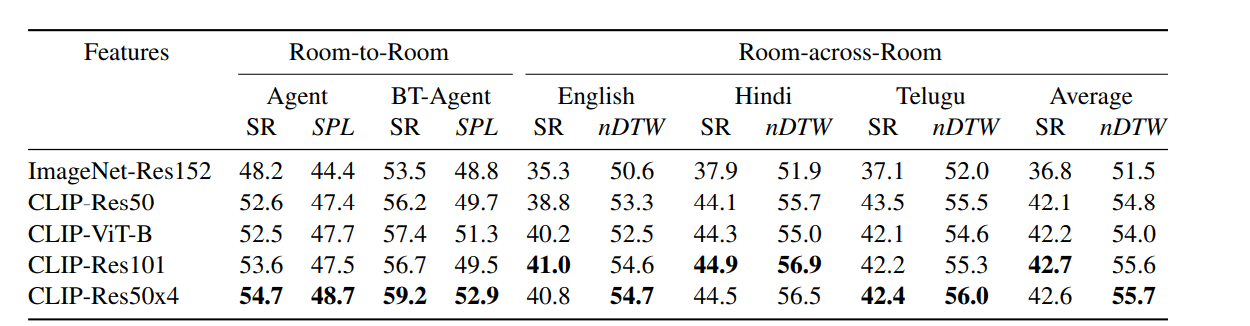
使用原始ResNet特征和CLIP特征变体的R2R和RxR数据集的结果。BT-Agent是用反向翻译(BT)训练的代理。SR是成功率。SPL和nDTW分别是R2R和RxR的主要指标。最好的结果是粗体。
CLIP-ViLp
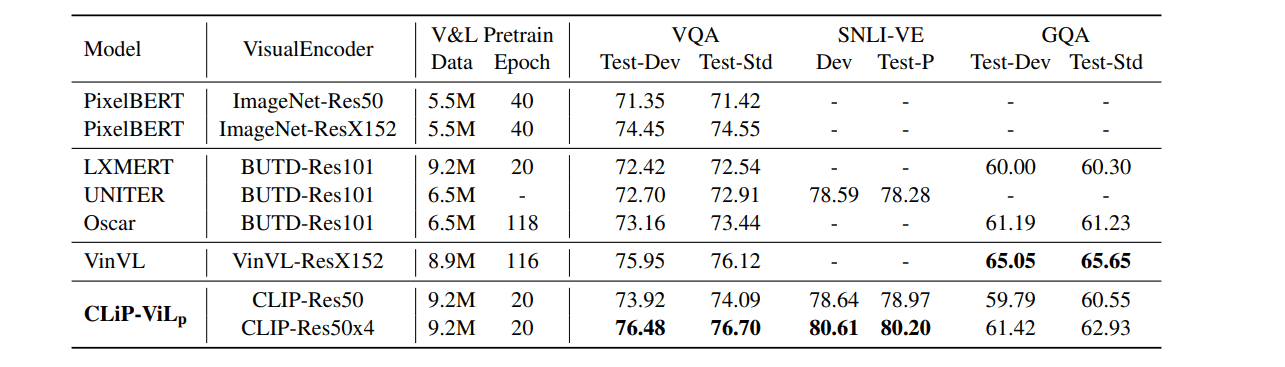
三个视觉和语言任务的评估结果。