Paper Reading: ViLBERT
本文提出了一个学习与任务无关的VLP模型,将BERT拓展到一个多模态的双流模型。通过co-atten进行不同模态的信息交互。
在大型的自动收集的数据集上预训练,可以容易的迁移到多种下游任务(MLM,VLM,MVM)。
将视觉基础(visual grounding)作为一种可预训练和迁移的能力。
介绍
VLP任务没有一个统一的方法提升不同模态的融合能力,通常先分别预训练语言和视觉模型,再通过微调学习文本与图像之间的grounding,通过这种方法学到的grounding并不可靠,如果数据量小,或存在大量噪音,那么模型的泛化能力会很差。
在单模态上拥有完美的模型,但无法在两个模态之间学习到联系,在下游任务中也没有什么用。因此,本文开发一个通用的visual grounding模型,在预训练中可以学习视觉与语言的联系,并在广泛的视觉和语言任务中利用它们——也就是说,我们寻求对visual grounding进行预训练。
为了学习视觉-语言的联合表征,本文使用多个代理任务(对图像进行着色或重建文本中的被屏蔽的词),以无监督的方式从大量没有标签的数据中学习丰富的语义和结构信息。本文使用一个视觉和语言能够对齐的数据源概念性标题数据集(Conceptual Caption)来学习模态之间的关系。
ViLTBERT从成对的图像-文本数据中学习与目标任务无关的visual grounding,扩展了BERT为每个模态引入了单独流,通过co-atten的Transofrmer层进行不同模态之间的信息交互。这种结构就可以适应每种模态的不同需求。
方法
一种直接的方法是对BERT进行最小的改动–通过聚类简单地将视觉输入空间离散化,将这些视觉token与文本输入完全一样,输入到预训练过的BERT,存在缺点:
- 将图像输入的空间离散化可能会导致失去视觉细节。
- 图像区域可能比句子中的单词有更弱的关系,而视觉特征本身往往已经是一个非常深入的网络的输出。
- 强迫预训练的权重去适应大量的额外的视觉
token,可能会损害学到的BERT语言模型。

为此,我们开发了一个双流架构,分别对每个模态进行建模,然后通过一小套基于注意力的互动来进行不同模态的融合。这种方法能在不同的深度上实现跨模态连接。
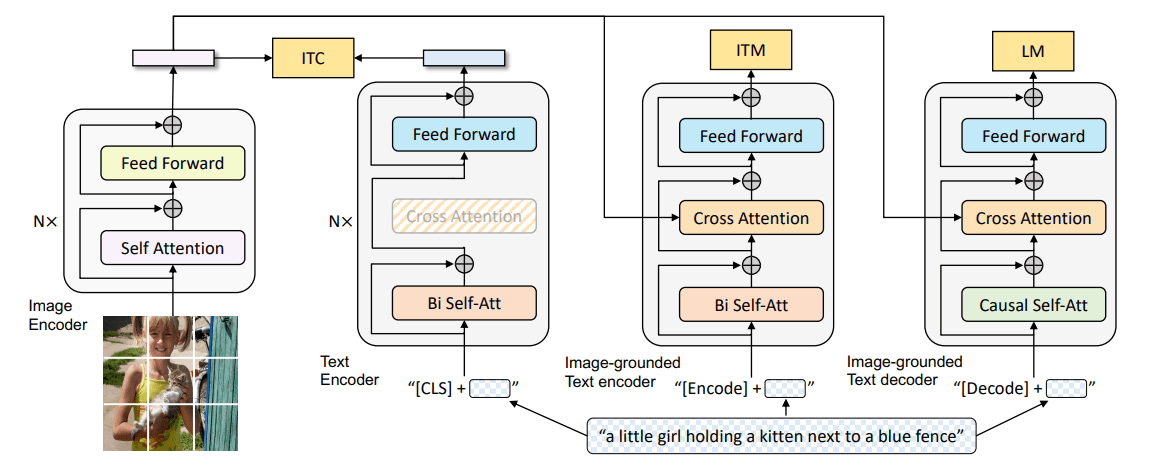
如图一所示,ViLBERT由两个平行的BERT模型组成,在图像区域和文本片段上运行。每个数据流都是一系列的Transforemr块(TRM)和co-atten transoformer层(Co-TRM)构成,我们引入这些变换器以实现不同模态之间的信息交互。两个流之间的交流被限制在特定的层之间,并且文本流在与视觉特征互动之前有明显更多的处理——视觉特征更加高级,与句子中的单词相比,只需要更有限的上下文汇总。
图像表示
从预先训练好的目标检测器中提取区域特征。我们对空间位置进行编码,构建一个5维矢量与边缘框的左上角坐标、右下角坐标、图像大小占比分别相加。使用代表整个图像的特殊IMG token作为图像序列的开始。
预训练任务
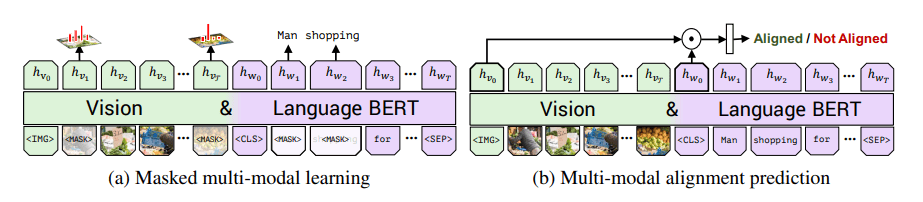
我们考虑两个预训练任务:
-
遮罩多模态建模。屏蔽 的图像区域和单词输入,让模型通过上下文信息重建它们。被遮罩的区域 的概率遮挡, 的概率保持不变。不直接对被遮蔽的图像特征值进行回归,而是预测相应图像区域的语义类别分布。为了监督这一点,我们从用于特征提取的同一预训练检测模型中获取该区域的输出分布。我们训练模型以最小化这两个分布之间的
KL散度。屏蔽文本输入的处理与BERT相同。 -
图文匹配。预测文字是否描述了图像,文章把输出的和作为视觉和语言输入的整体表示,借用视觉和语言模型的另一个常见结构,我们将整体表征计算为
IMG token位置的输出和CLS token位置的输出之间的元素乘积,并学习一个线性层来进预测。为了生成负样本,我们随机地将图像或标题替换成其他数据。