Paper Reading: Pixel-BERT
提出一个全新的可以端到端学习的模型Pixel-BERT,不基于区域的图像特征,将图片像素与文本对齐,克服区域特征的语义标签与语言语义之间的不平很,在图像与文本之间建立更加准确的联系。
介绍
基于区域的特征是为特定任务设计的,与语言理解的信息存在差距,同时特征的表示能力受限于训练时的给定种类,且边界框的背景会带来噪声信息,丢失目标的状态、对象之间的空间关系等。
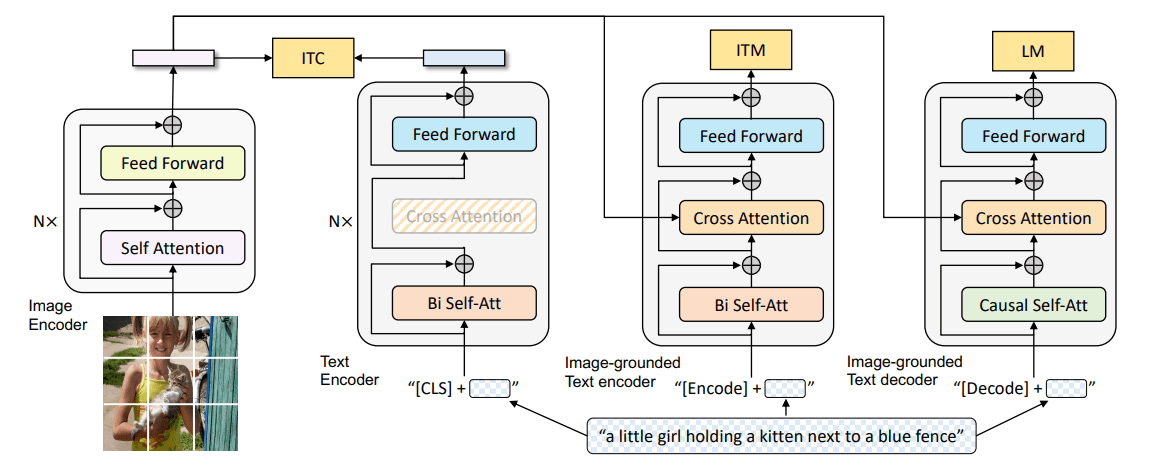
因此本文提出Pixel-BERT,学习将图像像素与文本对齐。Pixel-BERT由三部分组成:
- 用于视觉特征提取的
CNN(例如ResNet) - 和
BERT训练时方法一致的文本嵌入。 - 用于融合视觉模态和语言模态的
Transformer
对于预训练与先前的模式相同:
- 文本掩码重建(
MLM) - 图文配对(
ITM)
同时本文也提出了新的随机像素采样机制,以提高视觉模态上的鲁棒性。
方法

边界框特征包含嘈杂的背景,丢失了空间信息,为了充分利用视觉信息,本文的方法通过学习像素的视觉嵌入来完成文本-视觉任务。
文本特征嵌入
如BERT的方式一致,将句子分割为单词,使用WordPiece将每个单词标记为token,使用一个嵌入矩阵将每个标记嵌入到一个向量中 ,同时加上位置嵌入与一个区分模态差异的语义嵌入并使用Layer Norm
得到最终的语言嵌入向量。
图像特征嵌入
使用一个卷积神经网络输入图像得到特征图,将特征图沿着空间维度平铺得到长度为 的像素特征 ,对像素特征中的每个元素和语义嵌入相加
得到最总的图像嵌入。
模态融合
将语言嵌入向量与图像嵌入向量拼接起来,并在序列开头插入用于学习分类的[cls] token以及在不同模态嵌入向量之间插入[sep] token得到的序列
作为用于模态融合的Transformer的输入。
CNN和Transformer合并为单个模型,以端到端的方式训练。
预训练
文本掩码重建
本文以 的概率随机掩盖语言标记,并要求模型根据其他非掩盖的标记和视觉标记来预测掩盖的标记。
图文配对
在训练过程中,我们对数据集提供的所有图像-句子对进行抽样,并将其视为正样本。我们还随机洗牌数据集,将不匹配的图像-句子对视为负样本。为了防止学习偏差,我们采用相同数量的正样本和负样本。
像素随机采样
为了提高特征学习的鲁棒性,避免过拟合,在预训练中随机抽取特征像素。这样的像素随机抽样可以在两个方面有利于模型的训练。
- 它可以鼓励模型从不完整的视觉输入中学习语义知识,从而增强鲁棒性。
- 它可以减少输入元素的数量,从而降低计算成本,加快训练进度。
在我们的实验中,我们将从每张输入图像的特征图中随机抽取固定数量的 个像素。