Paper Reading: ViLT
目前的VLP相比于文本更依赖于图像的特征提取过程:
- 效率低下,输入特征提取甚至比模态融合更复杂。
- 表达能力受限于预训练的视觉嵌入及其预定义的视觉词汇。
为此,本文提出ViLT,以统一的方式处理图像和文本信息:
ViLT是目前最简单的多模态(视觉-语言)模型。- 在不使用区域特征和
CNN的情况下,取得了合格的性能。 - 首次在
VLP训练中,使用了全词遮罩和图像增强。
Introduction
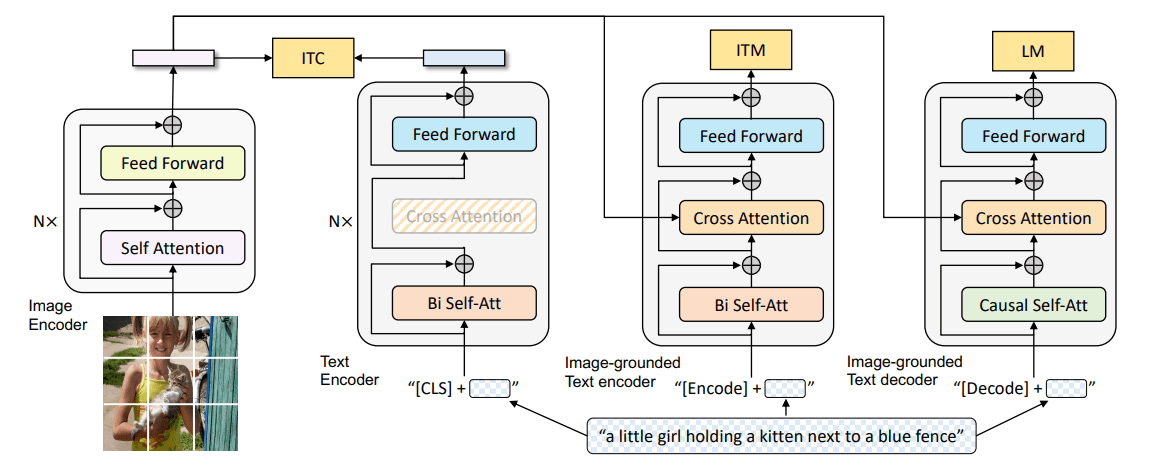
VLP在预训练中,通常同时使用图文匹配和**重建文本(Mask)**两种方式,在下游任务上微调。

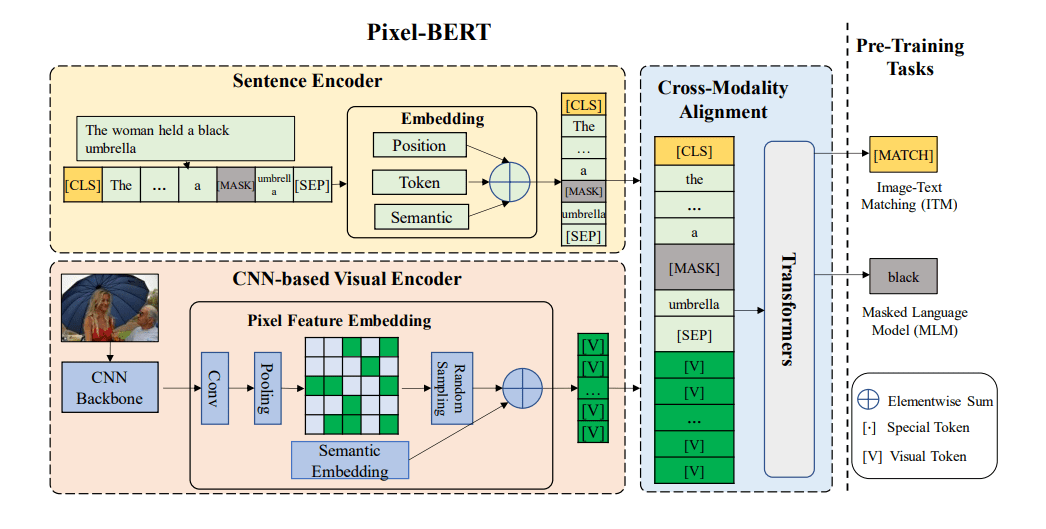
为了输入Transformer,原始图像输入需要被转换为另一种形式与文本一起输入,大部分工作在图像嵌入上使用一个预训练好的目标检测器,将密集的图像像素离散化(多个边缘框)。Pixel-BERT是一个例外,其使用一个预训练好的残差网络,直接将网络的特征输出作为一个离散的序列作为Transformer的输入,在速度上大大提高。但是目前仍然集中研究通过提升图像嵌入的性能以提高整体的性能而并未考虑速度,虽然可以将图像特征预先抽取,保存在本地硬盘上,但是对于现实任务,需要在线学习时仍然非常耗时。

为此,本文受ViT启发,将图像分割为Patch,使用一个简单的线性层,将Patch转换为嵌入,直接作为Transformer的输入。速度相比于先前的模型大大提升,性能也在合格的范围,相比于更耗时的Pixel-BERT-R50甚至性能有所提升,如上图所示。
背景
模型分类
本文提出两个视觉-语言模型的分类依据,划分为四个不同类别:
- 两种模态的专用参数或计算量是否相称。
- 两种模式是否在一个深度的网络中相互作用。

如上图
- a) 视觉嵌入比文本嵌入更大,而模态融合最轻量(点乘,或浅层神经网络),多为早期的工作,如,
VSE。 - b) 视觉嵌入与文本嵌入计算量相仿,而模态融合轻量,适合特征抽取,但是在
VLP的下游任务中效果不佳,如,CLIP。 - c) 视觉嵌入比模态融合更复杂,而文本嵌入最轻量,性能很好,但是速度不佳,如,
ViLBERT、VisualBert、UNITER等等。 - d) 视觉嵌入与文本嵌入一样轻量,模态融合最复杂,即本文的
ViLT
模态融合
- 单流(single-stream):一个模态融合模型处理两个模态的输入,通常直接将两个输入拼接在一起
- 双流(dual-stream):分别处理两个模态,再通过一些网络进行融合。一般来说参数量会更多。
视觉特征抽取
- Region Feature:Backbone(例如
ResNet)抽取特征->RPN提取ROI->NMS降低数量到输入序列长度->ROI head将序列转为一位向量。运行时间非常高。 - Grid Feature:直接将
Backbone网络的特征输出作为Transformer的输入。性能不佳。 - Patch Projection:即本文方法,受
ViT启发,只使用一层Patch Projection抽取图像特征。
方法
模型概览

文本信息通过Word Embedding得到一个 的输出,图像分割为 的Patch经过Linear Projection得到 的输出(本文)。
图像特征与文本特征分别加上(而不是拼接)模态嵌入(文本为,图像为)与位置嵌入,和cls token嵌入拼接在一起得到一个 的嵌入,作为Transformer Encoder的输入。
训练
同时优化两个目标:
- 图文配对: 的概率将文本对应的图片替换成不同的图片,对文本
cls token的输出使用一个线性的ITM头判断图文是否配对。 - 文本重建:预测被
Mask的文本,其中遮罩将整个单词遮住,而非一个单独的词根。以避免模型学得捷径。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Toby的小博客!
相关推荐

评论


