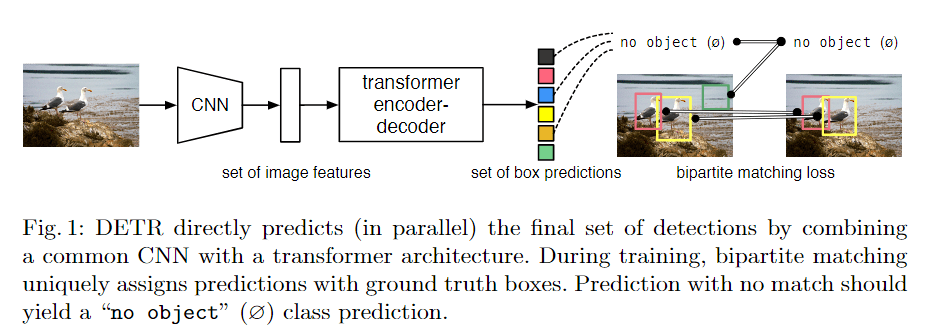
Paper Reading: MAE
简介
Masked Autoencoders(MAE)是用于计算机视觉中的自监督方法。MAE的方法非常简单:我们随机遮住输入图像的一些patch然后重建缺失的像素。
MAE基于两个架构:
- 我们开发了一个非对称
编码器-解码器架构,编码器只在可见patch子集上计算(不计算被遮住的patch以节省时间),以及一个轻量级解码器,该解码器根据潜在表示和掩码token重建原始图像。 - 我们发现高比例的遮盖输入图像(如 )会产生意义非凡的自监督任务,展现了很强的迁移性能。
结合这两种设计使我们能够有效地训练大型模型:我们加速训练3倍以上,并提高了准确性。

对数据的需求已经在NLP中通过自监督的预训练得到了成功的解决。这些解决方案基于GPT中的自回归语言建模和BERT中的Masked Autoencoders,在概念上很简单:它们删除了一部分数据并学习预测删除的内容。Masked Autoencoders的想法,是一种更普遍的去噪自动编码器的形式,很自然,也适用于计算机视觉中。但视觉中的自动编码方法的进展却落后于NLP,原因是:
- 结构差异,
NLP中是Transformer,而CV主流的仍然是CNN,ViT的提出解决了这个问题。 - 信息细粒度的差距,
NLP是高信息密度的,语义信息强,重构难度大,而CV中的像素是信息匮乏的,直接插值,都可以得出不错的结果。本文按patch高比例的遮罩输入图像制造了高难度的任务。

方法
我们的MAE是一种简单的自动编码方法,在给定其部分观察的情况下重建原始信号。包含一个将观察到的信号映射到潜像的编码器,以及一个从潜像中重建原始信号的解码器。
遮罩
如同ViT一样,我们分割图像到规整的不重叠的多个patch。然后,我们按照均匀分布对随机斑块进行无替换抽样,并对剩余的补丁进行遮蔽。
具有高遮蔽率()的随机抽样在很大程度上消除了冗余信息,从而创造了一个不能通过从可见的相邻斑块推断而轻易解决的任务。

编码器
我们的编码器是一个ViT,但只适用于未被掩盖的斑块(我们的编码器只对全集的一个小子集进行操作。 屏蔽的patch被删除,不使用屏蔽标记)。如标准的ViT中一样,我们的编码器通过线性投影嵌入补丁,并添加位置嵌入。
这使我们能够用一小部分计算和内存来训练非常大的编码器。
解码器
解码器的输入是由编码的可见斑块和掩码标记组成的全套标记,见图二。
每个掩码标记[14]是一个共享的、学习过的向量,表示有一个要预测的缺失补丁。我们在这个完整的集合中为所有的标记添加了位置嵌入;解码器有另一系列的Transformer块。
MAE解码器只在预训练期间用于执行图像重建任务(只有编码器用于产生用于识别的图像表示)。 因此,解码器的结构可以以独立于编码器的设计方式十分灵活。我们尝试使用非常小的解码器,比编码器更窄、更浅。例如,我们的默认解码器与编码器相比,每个令牌的计算量 。通过这种不对称的设计,全套的标记只由轻量级的解码器处理,这大大减少了预训练时间。