Paper Reading: DALL-E 2
介绍
像CLIP这样的对比学习模型可以学习稳健的图像表征,这些表征可以捕捉到语义和风格。为了利用这些表征来生成图像,我们提出了一个两阶段的模型:给定文本生成图像特征,称为prior(在这里训练完的CLIP所产生的图像特征作为ground truth),以及以图像嵌入为条件生成图像的解码器(均使用扩散模型)。
我们表明,显示的生成图像特征可以提高生成图像的多样性,而在逼真度和(标题)相似度方面没有什么损失。解码器基于给定的图像特征所生成的图片在风格上与语义相近,但是在特征中未包含的不必要的细节有所不同。


通过CLIP作为桥梁,能够达到通过文本直接对图像进行编辑的功能,并且是zero-shot的。
模型的选择
CLIP:通过简单的对比学习,就能学习到稳健的特征(例如对于分布偏移)。且拥有特别好的zero-shot能力。
扩散模型:在图像生成领域都达到了SOTA。是一个概率分布模型,多样性极佳,且经过优化(例如guidance technique)在保真度上也可以和GAN不相上下。
方法

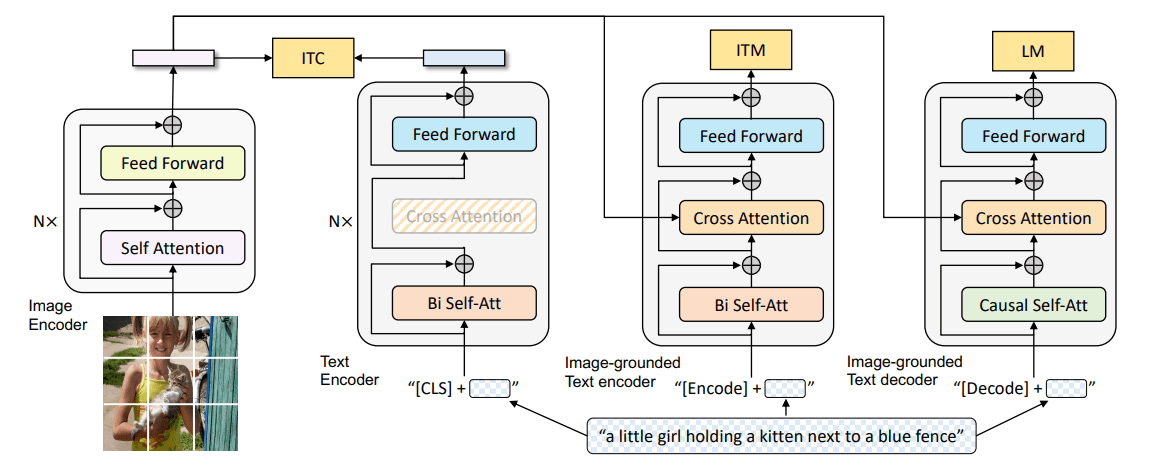
如上图,虚线上方的是一个CLIP模型(文本编码器得到一个文本特征,图像编码器得到一个图像特征),CLIP训练完后被锁住,此时CLIP中的图像特征作作为ground truth监督prior给定文本特征(通过CLIP中锁住的文本编码器)生成图像特征。随后再经过一个扩散模型解码器。
训练数据集由一对 的图像 和他们相应的标题 组成。给定图片 ,CLIP生成图像特征 和文本特征 。我们使用层级式的设计,分为两个步骤从标题中生成图像:
- 一个
prior产生以标题 为条件的CLIP图像特征 。 - 一个
decoder产生以CLIP图像特征 为条件的图像 (以及可选择的文本标题 )
将这两个组件堆叠在一起,生成图像的生成模型 ,给定标题 (两阶段设计的合理性):
其中, 与 为对等的,下一步通过 chain rule可以得出。
Decoder
本文中的Decoder是一个GLIDE的变体,使用了CLIP guidance,本文也使用了classifier-free guidance。
训练时 的时间把CLIP的特征设置为 ,的时间直接将文本特征丢弃。
使用级联式的生成,先从 生成到 ,再训练一个模型从 生成到 。
本文只用了卷积而无自注意力,所以没有序列长度的限制。
Prior
也使用了classifier-free guidance。
对于扩散模型,训练了一个Transformer Decoder,代替 U-Net 处理序列数据。输入了文本,CLIP的文本特征,timestep embedding,加入噪声后的CLIP图像特征以及Transformer自身的embedding(如cls token),最终的embedding特征被拿去预测没有加入噪声的CLIP图像特征。
训练上与先前的扩散模型没有区别,但是Prior对于特征重建,直接预测图像特征比预测噪声效果更好,为此我们使用均方误差损失: