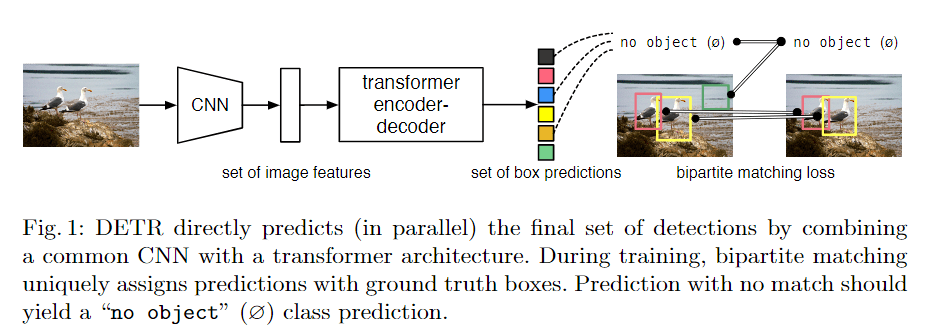
Paper Reading: Swin Transformer
简介
我们力图扩大Transformer的适用范围,使其能够成为计算机视觉的通用骨干。
其在语言领域的高性能转移到视觉领域的重大挑战可以用两种模式之间的差异来解释:
- 图片的形状是可变的,在现有的基于
Transformer的模型中,token都是固定形状的。 - 图像中的像素分辨率比文本中的单词“分辨率”高得多。
例如语义分割这类稠密预测对于现有的Transformer模型来说是难以实现的,因为他的自注意力计算复杂度是与图像大小成平方倍增长
为了解决这些问题,我们提出了一种通用Transformer骨干网络,称为 Swin Transformer

如上图,其构建了层次化的特征图,可以方便地利用于密集预测的先进技术,且计算复杂度是随着图片大小线性增长,通过只在分割图像的非重叠窗口内局部计算自注意来实现的(window self-attention)。
每个窗口中的Patch数量是固定的,因此复杂度与图像大小成线性关系。
Swin Transformer的一个关键设计元素是其在连续的自注意力层中滑动分割窗口。
如下图,移位后的窗口与前一层的窗口相接,以提供它们之间的联系,大大增强了网络的建模能力。

在第一层(左),采用了一个常规的窗口划分方案,并在每个窗口内计算自注意力。 在下一层(右),窗口的划分被改变,重新产生新的窗口。在新的窗口中,自注意的计算跨越了前一层先前窗口的边界,提供了它们之间的联系。
方法
总体架构

Swin-T(微小版本)
首先将输入通过一个分割模块分割成不重叠的patch,每个patch都会被处理为一个token。
在我们的实现中,我们使用 的补丁尺寸,因此每个补丁的特征维度是 。
一个线性嵌入层将原始值的特征投影到一个任意的维度。
随后几个Swin Transformer block (具有修改过的自注意力计算的Transformer块) 作用于这些token。
Swin Transformer block保持了token的数量( ),并与线性嵌入一起被称为“阶段1”。
为了产生分层的表示,随着网络的深入,通过patch合并层来减少token的数量。
第一个patch合并层将每组 相邻的patch的特征连接起来,并在 维拼接的特征上应用一个线性层,输出维度被设置为 。
之后应用Swin Transformer块进行特征变换,分辨率保持为 。
这第一块patch合并层和特征转换被称为“阶段2”
该程序重复两次,作为“阶段3”和“阶段4”,输出分辨率分别为 和 。
他们产生了如同经典卷积神经网络一样的不同层次的特征表示,因此,所提出的架构可以方便地取代现有方法中的骨干网络,用于各种视觉任务。
Swin Transformer block
Swin Transformer 是通过将Transformer块中的标准多头自注意力(MSA)模块替换为基于滑动窗口自注意力(SW-MSA)的模块来建立的,其他的层保持一致。
如上图中的b所示,一个Swin Transformer块由一个SW-MSA模块组成,一个双层MLP,中间有GELU。在每个SW-MSA模块和每个MLP之前都有一个LayerNorm(LN)层,每个模块之后都有一个残差连接。
基于滑动窗口的自注意力
全局计算导致了标准自注意力与随着token数量平方倍增长的计算复杂度,使得它不适合密集预测的视觉问题,也不适合处理高分辨率的输入。
非重叠窗口中的自注意力
假设每个窗口包含 个patch,全局 MSA 模块和基于窗口的自注意力 个patch的图像的计算复杂性为:
在连续的块中进行滑动窗口划分
仅基于窗口的自注意模块缺乏跨窗口的交互,这限制了其建模能力。
为了引入跨窗口间的交互,同时保持非重叠窗口的有效计算,我们提出了一种移位窗口划分的方法,在连续的Swin Transformer块中交替使用两种划分策略。
如第一张图所示,第一个模块使用常规的窗口划分策略,从左上角的像素开始划分—— 的特征图被分割为 个大小为 的窗口( )。
下一个模块采用与前一层不同的窗口划分策略,通过将窗口从规则分区的窗口中移出 (本文中为)个像素来实现。
用移窗分割的方法,连续的Swin Transformer块被计算为
其中W-MSA和SW-MSA分别表示基于常规窗口和滑动的窗口的多头自注意力。
用于高效的批量计算的滑动策略
移位窗口分区的一个问题是,它将产生更多的窗口,从 到 ,且一些窗口小于 。
一个的解决方案是将较小的窗口填充到 的大小,并在计算注意力时屏蔽掉填充的值。
我们提出了一种更有效的批量计算方法,即向左上角方向的循环移动,如下图所示。

C从底下移到了上面,B从左边移到了右边,A从右下移到了左上
在这种转换之后,一个patch窗口可能由特征图中不相邻的几个子窗口组成,因此,我们采用了一种遮罩机制,将自注意的计算限制在每个子窗口内。
相对位置偏置
在计算自我注意时,我们遵循前人的做法,在计算相似性时,对每个头都引入一个相对位置偏差 :
其中 Value , 是 query和key的维度,是一个窗口中patch的数量。
由于沿每个轴的相对位置位于 的范围内,我们对一个较小尺寸的偏置矩阵进行参数化,中的值取自
预训练中学习到的相对位置偏差也可用于初始化模型,通过双三次差值插值,用不同的窗口大小进行微调。
变体
我们建立了我们的基础模型,称为Swin-B,其模型大小和计算复杂性与ViT-B/DeiT-B相似。
我们还介绍了Swin-T、Swin-S和Swin-L,这三个版本的模型大小和计算复杂度分别约为倍、倍和倍
窗口大小默认设置为 。在所有的实验中,每个自注意力头部的query尺寸为,每个MLP的扩展层为 。 这些模型变体的结构超参数为:
-
Swin-T: ,层数=
-
Swin-S: ,层数=
-
Swin-B: ,层数=
-
Swin-L: ,层数=