最优化理论与算法: 单纯形法
完全形法的主要思想是,从一个初始基本可行解开始,迭代改进可行解,直到达到最优。
基本概念
对于线性规划的标准形式:
minf≡cxs.t.Ax=bx≥0\begin{aligned}
\min &&f &\equiv cx \\
\text{s.t.}&& Ax&=b \\
&& x &\geq 0
\end{aligned}
mins.t.fAxx≡cx=b≥0
通过变换行,使其前 mmm 行线性无关,对矩阵AAA的分割,得到基矩阵 BBB 与非基矩阵 NNN:
Am×n=(P1,P2,...,Pm,Pm+1,...,Pn)=(B,N)\underset{m \times n}{A} = (P_1,P_2,...,P_m,P_{m+1},...,P_n) = (B,N)
m×nA=(P1,P2,...,Pm,Pm+1,...,Pn)=(B,N)
同样对CCC、xxx进行划分得到(CB,CN)(C_B,C_N)(CB,CN) (xB,xN)(x_B,x_N)(xB,xN)
初 ...

Paper Reading: YOLOPv2
多任务学习方法解决全景驾驶感知问题方面提供了高精度和高效率的性能。已经成为在计算资源有限的情况下,设计自动驾驶系统网络的流行范式。
本文提出一个有效的多任务学习网络,同时执行目标检测,可驾驶道路区域分割,和车道线检测。
更好:提出了一个更有效的模型结构,开发了更复杂的bag-of-freebies,例如在数据域处理时进行mosaic与mixup,应用了一种新的混合损失。
更快:为模型实施了一个更有效的网络结构和内存分配策略。
健壮:在一个强大的网络架构下训练出来的,因此它有很好的通用性,可以适应各种情况,同时保证速度。
在BDD100K数据集上,取得了SOTA水平,且推理时间大幅度减少。
方法
我们在一系列现有工作(YOLOP、HybridNet等)的基础上设计了一个更有效地网络。我们利用解码器头的三个分支来执行具体任务,而不是在同一个分支中运行可驾驶区域分割和车道线检测任务,因为我们观察到可驾驶区域分割和车道检测的任务难度完全不同,意味着对特征层面的要求不同,因此最好有不同的网络结构。
网络架构
他由一个共享编码器和三个解码器头组成,前者提取输入图像特征,后者完成相应任务。 ...

Paper Reading: An Image is Worth One Word
通过自然语言指导创作,Text-to-Image达到了极高的创作自由度,但是仍然难以通过语言指导生成特定概念的图像,修改它们的外观,或将他们组成新的角色和新的场景。
本文提出了一种允许这种创作的简单方法:
使用给定的3-5张图像,学习在冻结的Text-to-Image的嵌入空间中通过新的“单词”描述它。
这些“单词”可以组合成自然语言句子,指导个性化创作。
我们发现,单个单词足以捕获多样的概念。
主要贡献:
介绍了个性化的文本到图像生成任务,在自然语言指导下合成了用户提供的概念的新颖场景。
提出文本反转想法,目标是在文本编码器的嵌入空间中寻找新的伪词,这些伪词可以捕捉到高级语义和精细的视觉细节。
介绍
最近的大规模Text-to-Image模型展现出了对自然语言描述进行推理的前所未有的能力。允许用户用从未见过的构图合成新奇的场景,以无数种风格产生生动图片。然而,它们的使用受制于用户通过文本描述所需目标的能力。
在大规模的模型中引入新的概念往往非常困难。重新训练模型非常昂贵,对少数例子进行微调通常会导致灾难性的遗忘。更多的方法是冻结了模型并训练变换模块以在面对新的概念时调整输出 ...

Paper Reading: Pre-trained Models for Natural Language Processing: A Survey
本文为NLP的PTM提供了一个整体的回顾。
语言表征学习
从多个角度对现有PTM进行系统的分类,
下游任务
未来研究的潜在方向
PTM - Pre-trained Models
背景
语言表征学习
在NLP中,一个好的表征应该捕获文本中的潜在语言规则和常识性知识(如词义,语法结构等)。
分布式表征(词向量):用低维的实值向量表述文字。向量的每个维度都没有相应意义。
词嵌入:有两种词嵌入非语境(non-contextual)与语境下(contextual)的词嵌入,后者代表其会根随词所在的语境而动态变化。
非语境词嵌入
通过查表(词数量 ∣V∣|\mathcal{V}|∣V∣ 固定,嵌入向量维度 DeD_eDe 固定)的方式,将每个单词(或子词)映射到一个嵌入向量。
给定一个词表 V\mathcal{V}V 中的单词 xxx,通过查表 E∈RDe×∣V∣E \in \mathbb{R}^{D_e \times |\mathcal{V}|}E∈RDe×∣V∣ 映射到一个向量 ex∈RDee_x \in \mathbb{R}^{D_e}ex∈RDe,其中 DeD_eDe ...

Paper Reading: METER
最近的工作表明,完全基于Transformer的模型比OD-RFs的模型更有效。但它们在下游任务上的表现往往会明显下降。
本文提出METER,一个多模态的端到端Transformer框架。
沿着多个维度剖析了模型设计:视觉编码器、文本编码器、多模态融合模块、架构设计,以及预训练目标。
介绍
视觉Transformer(ViTs)在视觉特征提取方面显示出巨大的潜力。因此,本文使用ViTs作为图像编码器训练一个完全基于Transformer的VLP模型。
最近试图采用视觉Transformer仍然弱于最先进的OD-RFs模型。为了缩小性能差距,我们提出了METER,一个多模态的端到端Transformer框架,通过它我们彻底研究了如何以端到端方式设计和预训练一个完全基于Transformer的VLP模型。
我们沿着多个维度对模型设计进行剖析
视觉编码器,如CLIP-ViT、Swin Transformer
文本编码器,如RoBERTa、DeBERTa
多模态融合模块,如合并注意力(merged attention)、共同注意力(co-attention)
架构设计,仅编码器与编码器-解 ...

Paper Reading: VLP 综述
本文调查了视觉语言预训练(VLP)的最新进展和新领域,包括图像-文本和视频-文本预训练。
Feature Extraction 特征提取
如何对图像、视频和文本进行预处理和表示,以获得对应的特征
图像
(1) 基于目标检测的区域特征(OD-RFs)
利用预训练好的目标检测器(最常用的是带有自下而上注意力的Faster R-CNN)来提取视觉特征。
将OD输出的 204820482048-d 区域特征嵌入,以及对边界框和空间位置(边缘框左上角坐标、右下角坐标、图像大小占比)嵌入到高维 204820482048-d的视觉几何嵌入,两者相加作为基于目标检测的区域特征(OD-RFs)。
提取区域特征很费时,为了缓解这个问题,区域特征通常被预先抽取存储在磁盘上,而OD则在训练期间被冻结,但也带来了负面影响(限制了VLP模型的容量,受限于OD训练时的固定词汇等)
e.g. VIsualBERT ViLBERT
(2) 基于CNN的网格特征(CNN-GFs)
利用卷积神经网络(CNN)得到网格特征。
通过直接使用网格特征作为视觉特征来对CNN进行端到端的训练。
也可以先用学习到的视觉字典离 ...
Paper Reading: ImageBERT
由人类手动编写的图像描述是高质量的,但十分昂贵。为了利用互联网上有无数的网页相关的图像。本文设计了一种弱监督的方法收集来自网络的大规模图文对数据。由此产生的数据集LAIT(Large-scale weAk-supervised Image-Text)包含1000万张图片以及平均长度为13个单词的描述。我们将在实验中表明,LAIT对视觉语言预训练是有益的。
方法
从网络上抓取数十亿的网页
Web-page Collection:
丢弃非英语的网页
我们解析每个网页收集图像URL
通过HTML标签和DOM树的特征检测主导图像。
非主导图像被丢弃
Image Content Based Filtering:
只保留宽度和高度都大于300像素的图片。
过滤不和谐图片。
应用二元分类器来丢弃不自然的、不真实的和不可读的图像。
Sentence Detection & Cleaning:
使用以下数据源作为图片的文本描述:
HTML中用户定义的元数据,如Alt或Title属性,
图片的周围文本等;
我们制定了一系列启发式规则
过滤掉句子中的不良跨度和噪声词(垃圾邮件/色 ...
Paper Reading: CLIP-ViL
在大量从网络获取的图文对上训练的CLIP在下游任务上表现出了强大的0-shot能力。为了挖掘CLIP在V&L任务所带来的优势,本文提出在两个场景使用CLIP作为视觉编码器:
插入CLIP到特定任务微调。
将CLIP与V&L模型共同训练。
Introduction
最近的工作观测到视觉表示成为为V&L模型的性能瓶颈,学习强大视觉编码器对于V&L模型是至关重要的。
但是现在广泛使用的视觉编码器使用手动标注的数据集训练,标注成本高,且视觉表征能力受到预先定义的类别标签的限制。所以,需要一种不受固定标签集限制,对未见过的物体和概念具有概括能力的视觉编码器,能够在大规模数据集上预训练。
最近CLIP被提出用来基于语言监督学习视觉概念。它是在从互联网上抓取的4亿个噪声图像文本对上训练的,并需要很少的人类注释。且有强大的0-shot能力。然而,直接将CLIP作为0-shot模型应用于V&L任务被证明是困难的,因为许多V&L任务需要复杂的多模式推理。
本文首次对使用CLIP作为V&L任务的视觉编码器的大规模实证研究->
将CLIP插 ...
ITerationT 3.0.0 vs 2.0.0
3.0.0 在前 2.0.0 在后
ITerationT 3.0.0:https://www.bilibili.com/read/cv17966453
材质:https://www.curseforge.com/minecraft/texture-packs/xekr-square-pattern/files
建筑地图:https://www.planetminecraft.com/project/projet-d-une-ville-fictive-fran-aise-en-constuction-project-of-a-fictional-french-city-work-in-progress/
山崖
丛林
河流
洞穴
末地
地狱
水下
建筑
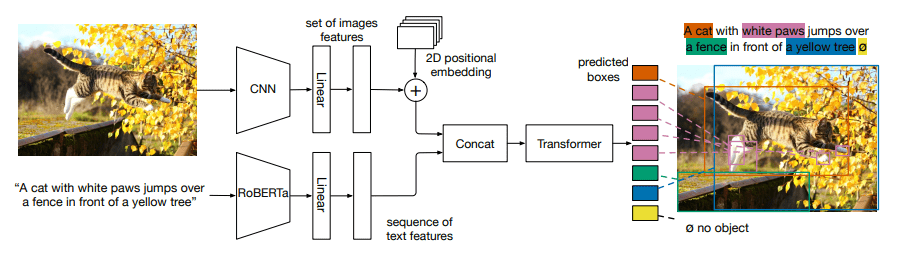
Paper Reading: MDETR
多模态推理依赖预先训练好的对象检测模型。这个模型多为一个黑盒,受限于训练时的固定词汇。这导致模型难以捕捉自由形式文本表达的视觉概念的长尾。
本文提出了一个基于DETR检测器的端到端文本调制检测系统。通过在早期阶段融合这两个模态,对文本和图像进行联合推理。对几个下游任务进行微调,例如短语定位、指代表达的理解和分割,获得SOTA。
介绍
多模态物体检测通常使用一个黑盒检测图像中的固定概念词汇表,然后进行对模态对齐,存在缺点:
训练时往往会将检测器冻住,限制了与其他模态作为上下文的共同训练,在微调时,妨碍了模型的进一步完善。
下游模型只能访问到检测到的物体,而缺乏全局信息。
意味着词汇应限制在检测器的类别和属性上,不能识别自由格式文本中表达的新的概念组合。
为此本文提出MDETR,基于DETR结合自然语言处理进行物体检测,实现真正的端到端多模态推理,MDETR依赖文本和对齐框作为图像中概念的监督形式。MDETR可以检测自由格式文本中的席位概念,能够理解自由的短语组合。
方法
我们使用预先训练好的Transformer语言模型对文本进行编码。然后,对图像和文本特征应用模式相关的线性投 ...