Paper Reading: I3D
介绍
本文提出了一个新的大型视频行为识别数据集Kinetics,包含400个动作类别,每个类别包含超过400个片段。比 HMDB-51 与 UCF-101高出了两个数量级。
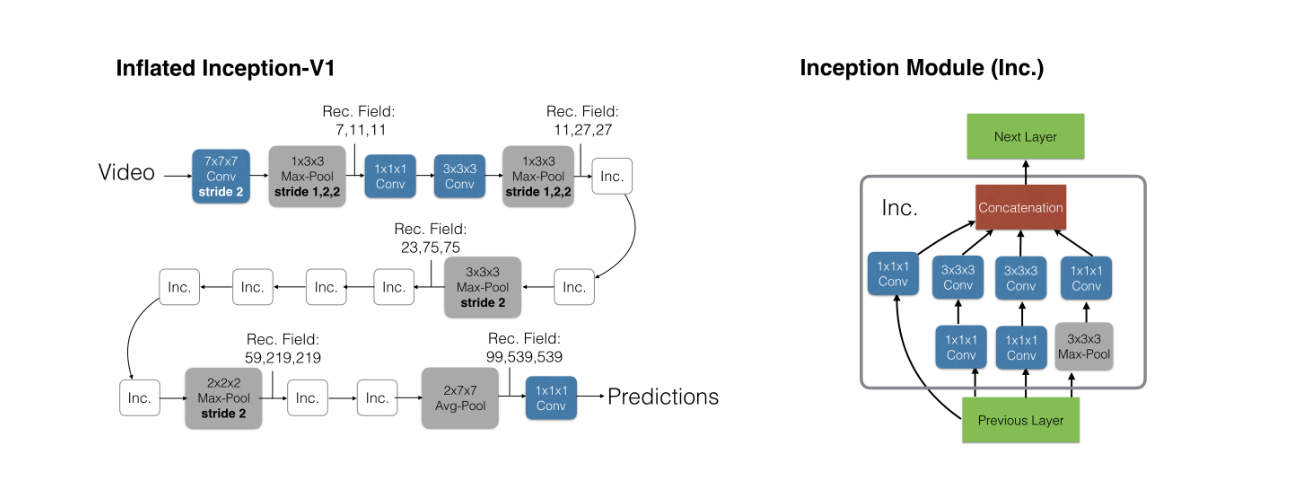
观察到视频理解相较于图片分类多了时间维度,所以本文将 2D 卷积的权重,扩展为 3D 卷积,提出了Two-Stream Inflated 3D ConvNet(I3D)模型。可以在大型数据集(如本文提出的Kinetics)上预训练,然后在小型数据集上进行微调。
基于 Inception-v1 的I3D模型,获得了远远超过先前SOTA的性能。
Two-Stream Inflated 3D ConvNets
通过这个架构,我们展示了3D 卷积神经网络可以从通过ImageNet预训练的 2D 卷积神经网络的权重中获益。
我们在这里也采用了双流结构,虽然3D卷积神经网络可以直接从RGB流中学习时许信息,但它们的性能仍然可以通过光流来大大提升。
扩张 2D 卷积到 3D
我们建议将成功的图像分类模型简单地转换为 3D 卷积神经网络。这可以通过从一个二维架构开始,将所有的卷积核与池化层膨胀起来——赋予它们一个额外的时间维 ...
Paper Reading: SiamFC
介绍
新的完全卷积的基于孪生结构的架构,名为Siamse,用于追踪任意物体,且不需要在线学习。
在初始离线阶段训练深度转换网络来解决更一般的相似性学习问题,然后在跟踪过程中在线简单地评估该函数。该方法在现代跟踪基准测试中以远远超过帧速率要求的速度实现了非常有竞争力的性能。
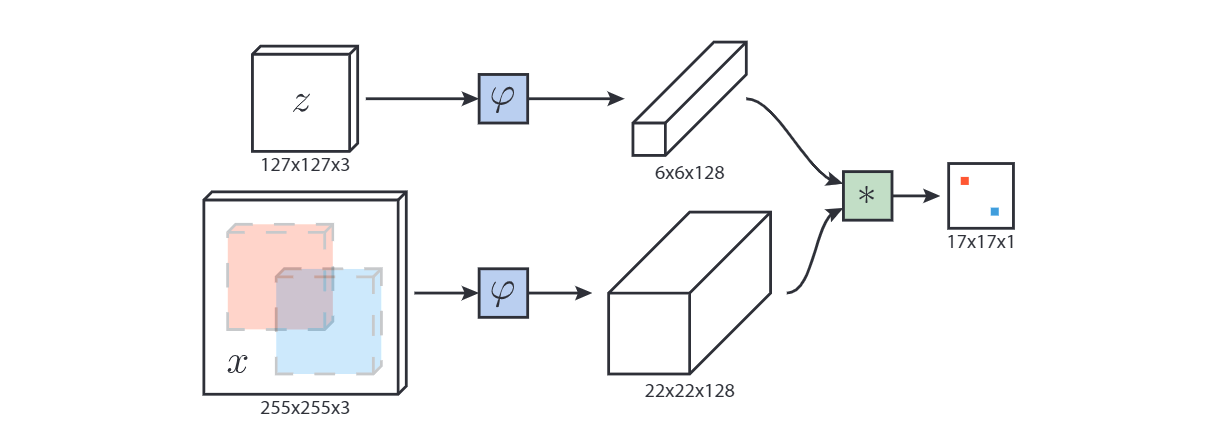
我们训练Siamese网络在较大的搜索图像中定位示例图像。需要跟踪的对象仅由第一帧中的矩形区域识别。
用于跟踪的深度相似学习
追踪任意物体的学习可以用相似性学习来解决。学习一个深度卷积神经网络 f(z,x)f(z,x)f(z,x) ,该函数将示例图像 zzz 与相同大小的候选图像 xxx 进行比较,返回相似度评分。为了找到物体在新图像中的位置,我们可以详尽地测试所有可能的位置,并选择与该物体过去的外观相似度最高的候选。在实验中,我们将简单地使用物体的初始外观(第一帧中的)作为典范。
深度卷积网络的相似性学习通常使用孪生结构来解决。孪生网络对两个输入应用相同的变换 φ\varphiφ,然后根据 f(z,x)=g(φ(z),φ(x))f(z,x)= g(\varphi(z), \varphi(x))f(z,x)=g( ...
Paper Reading: DeepID
介绍
DeepID可以通过具有挑战性的人脸分类任务有效地学习(把训练图像分类为nnn个身份之中的一个(在这项工作中 n≈10000n\approx 10000n≈10000)),预测任务比人脸验证更具挑战性,且有良好的泛化性。虽然是通过分类来学习的,但这些特征被证明对人脸验证和训练集中未见过的新面孔是有效的,其泛化性随着训练时要预测的人脸类别的增加而增加。
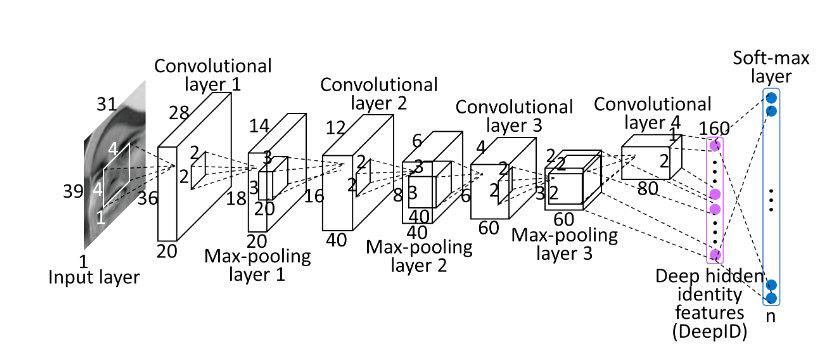
当作为分类器学习识别训练集中大约 100001000010000 个人脸身份,并配置为沿着特征提取层次不断减少神经元数量时,这些CNN特征数量沿着特征提取级联继续减少,最终在最后一层生成高度紧凑的 160160160 维DeepID。
学习DeepID进行人脸验证
深度卷积网络
我们的深层 ConvNets 包含四个卷积层(带最大池化),以分层提取特征,接下来是全连接的DeepID层和预测身份类别的softmax层。
网络的输入为 对于矩形 39×31×k39 \times 31 \times k39×31×k patch,以及 31×31×k31 \times 31 \times k31×31×k 的正方形 patch(彩 ...

Paper Reading: FaceNet
现有的方法无法大规模有效的实施人脸验证和识别。因此,我们提出了一种称为FaceNet的系统,该系统直接从人脸图像学习映射到紧凑( 128128128 维)的欧氏空间,其距离直接对应于人脸相似性的度量。一旦产生了这个空间,就可以很容易地基于FaceNet的嵌入向量使用k-NN进行人脸识别,K-means实现聚类。
我们的方法使用一个CNN进行训练,直接优化嵌入本身。而不是使用间接的和低效率的中间瓶颈层。为了训练,我们使用了用一种新颖的在线三联体挖掘方法生成的大致一致的匹配/不匹配的脸部patch的三联体(三个对脸部区域的紧密剪裁,除了缩放和平移之外,没有进行二维或三维对齐的裁剪。两个匹配的面部与一个不匹配的面部)。
我们实现了最先进的人脸识别性能,每张脸只用128字节。
我们还介绍了harmonic嵌入的概念,以及harmonic三联体损失,它描述了不同版本的脸部嵌入(由不同的网络产生),它们彼此兼容,并允许彼此之间进行直接比较。
为了提高聚类的准确性,我们还探索了hard-positive挖掘技术,鼓励对单个人的嵌入进行球形聚类。
关键词:三联体、harmonic嵌入、三联体损失。
...
Paper Reading: Exploiting Temporal Contexts with StridedTransformer for 3D Human Pose Estimation
介绍
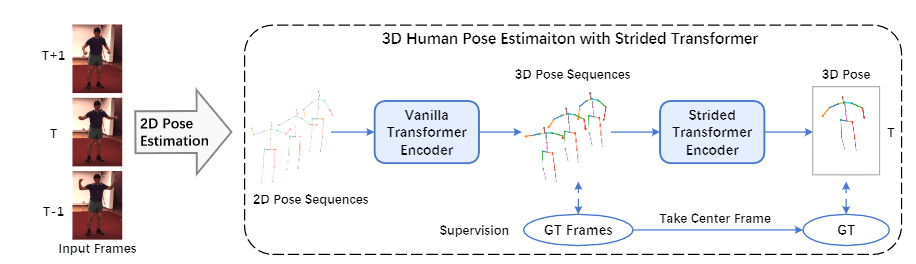
我们提出了一个新的基于Transformer的3D人体姿势估计架构,称为Strided Transformer,它可以简单有效地将一个长的2D姿势序列提升到一个单一的3D姿势。
为了减少序列冗余和计算成本,引入了Strided Transformer Encoder(STE)来逐步减少时间维度,并将长距离信息以分层的全局和局部方式聚合到姿势序列的单向量表示中。
设计了一个full-to-single的监督方案,在全序列规模的训练中施加额外的时间平滑性约束,并进一步完善单一目标帧规模的估计。
方法
给定从视频中估计出的2D位置序列 P={p1,...pT}P=\{p_1,...p_T\}P={p1,...pT} 我们旨在重建目标帧的三维关节位置 X∈RJ×3X \in \mathbb{R}^{J \times 3}X∈RJ×3 ,其中 pt∈RJ×2p_t \in \mathbb{R}^{J \times 2}pt∈RJ×2 表示 ttt 帧处的2D关节位置,TTT 是视频帧的数量,JJJ 是关节的数量。
该网络包含一个普通Transformer编码器(VTE),然后是 ...
Paper Reading: BYOL
介绍
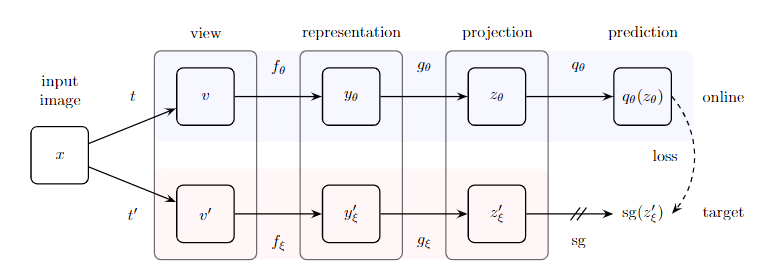
我们介绍了Bootstrap Your Own Latent(BYOL),这是一种自我监督的图像表征学习的新方法。
从一个图像的增强视图中,BYOL训练其online网络来预测target网络对同一图像的另一个增强视图的表示。
同时,我们用online网络的慢速动量的平均值来更新目标网络。
BYOL在没有negative pairs的情况下实现了新SOTA,且更具有鲁棒性。
背景
直接在表征空间中进行预测可能会导致表征的坍塌:例如,一个在不同视图中不变的表征总是完全预测自己。 对比法通过将预测问题重新表述为辨别问题来规避这一问题:从一个增强视图的表征中,他们学会辨别同一图像的另一个增强视图的表征,以及不同图像的增强视图的表征。然而,这种判别方法通常需要将增强后的视图的每个表现与许多负面的例子进行比较,以找到足够接近的例子,使判别任务具有挑战性。因此,我们的任务是找出这些负面的样本是否是防止坍塌同时保持高性能所不可或缺的。
一个简单的解决方案是使用一个固定的随机初始化网络来生成我们预测的目标。虽然避免了崩溃,但从实验上上看,它并不能产生很好的表征。尽管如此,值得注意的是,使用此 ...
Coding: 如何编写简单的深度学习程序
数据处理
12345678910111213141516171819202122232425root_dir = "xxx"train_dir = "xxx"class Dataset(object): def __init__(self, path, transform = None): self.xxx = xxx # 获取所有图片路径 self.image_paths = xxx # 获取所有图片的标签 self.labels = xxx ... def __len__(self): return len(self.inputs) def __getitem__(self, idx) # 对图像进行处理 image = Image.read(self.image_paths) # 读取图像 if transform is not None: image ...

Paper Reading: Convolutional Pose Machines
介绍
我们提出Convolutional Pose Machines(CPM)用于结构化预测(如铰接式姿态预测)
通过卷积架构的顺序组合学习隐性空间模型。对图像和多关键点之间的长距离依赖性的隐式学习,学习与推理之间紧密结合。序列化的,并将其与卷积架构所提供的优势相结合。能够直接用上一阶段网络输出的信念图(belief map)来产生越来越精细的关键点估计。
设计和训练这种架构的系统方法,以学习图像特征和图像相关的空间模型,用于结构化预测任务,而不需要任何图模型风格的推理。
方法
我们表示第p个标志的像素位置(我们称其为一个关键点), Yp∈ZY_p\in \mathcal{Z}Yp∈Z 其中 Z\mathcal{Z}Z 是图像中的所有坐标 (u,v)(u,v)(u,v)。
我们的目标是预测图像中所有 PPP 个关键点的位置 Y=(Y1,...,YP)Y=(Y_1,...,Y_P)Y=(Y1,...,YP)
pose machine 由一连串的多类别预测器组成 gt(⋅)g_t(\cdot)gt(⋅) ,训练他们以预测每个关键点在不同层次中的位置。对于每个阶段 t∈{1... ...
Paper Reading: Ultra Fast Structure-aware Deep Lane Detection
介绍
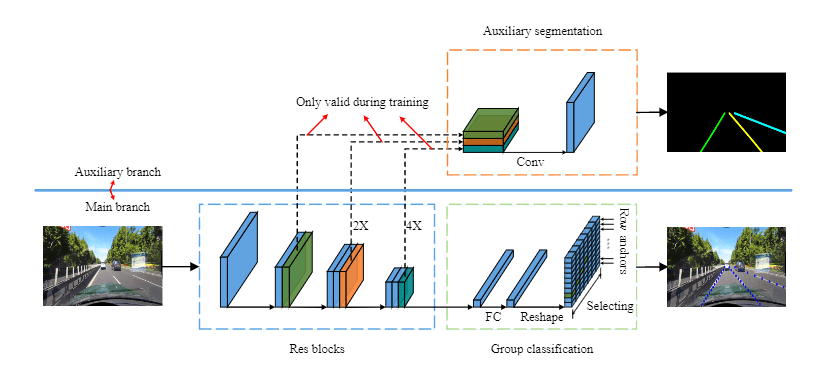
新颖、简单而有效的车道检测方案,通过选择车道的位置而非语义分割对每个像素进行预测,从而效率更高。使用全局特征预测,可以有效的解决无视觉线索的难题。
提出结构性损失,明确地利用车道的先验知识,如车道的刚性和平滑度等。
方法
车道线检测的新方法
本文方法的定义
将车道检测改转变为基于全局图像特征的行式选择方法,即使用全局特征在每个预定的行上选择正确的车道位置。
在我们的方法中,车道被表示为一系列预定的行中的水平位置,即行锚。在每个行锚上,位置被分为许多单元。以这种方式,车道的检测可以被描述为在预定的行锚上选择某些单元。
设最大车道数为 CCC,行锚数为 hhh,网格单元的数量为 www 。假设 XXX 是全局图像特征, fijf^{ij}fij 是用于选择第 iii 条车道线和第 jjj 行锚上的车道位置的分类器。那么车道的预测可以写成:
Pi,j,:=fij,s.t.i∈[1,C],j∈[1,h]P_{i,j,:}=f^{ij},\text{s.t.} i \in [1,C],j\in [1,h]
Pi,j,:=fij,s.t.i∈[1,C],j∈[1,h]
其中 ...
Paper Reading: DEtection TRansformer
介绍
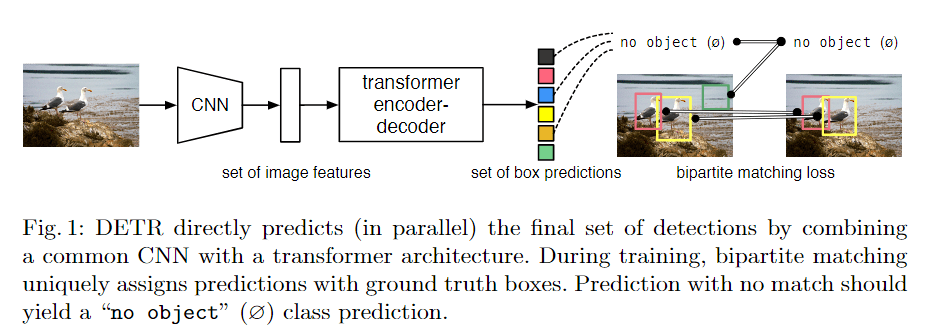
新框架的主要成分,称为DEtection TRansformer或DETR。
给定一个固定的小型学习对象查询集,DETR对对象的关系和全局图像背景进行推理,直接并行输出最终预测集。
抛弃了多个手工设计的编码先验知识的组件(如非极大抑制),简化了检测管道
DETR不需要任何自定义图层,所以可以在任何包含标准CNN和转化器类的框架中轻松重现。
DETR的主要特点是结合了双向匹配损失和变压器与(非自回归)并行解码
对大目标效果好,因为transformer的全局关注上的优势。
对小目标效果不好。需要FPN多尺度预测。
DETR模型
目标检测集合预测损失
DETR推断出一个固定大小的NNN个预测集,只需通过一次解码器,其中NNN被设定为明显大于图像中的物体数量。训练的主要困难之一是对预测的物体(类别、位置、大小)与地面实况进行评分。我们的损失在预测对象和地面真实对象之间产生一个最佳的双点匹配,然后优化特定对象(边界盒)的损失。
让我们用yyy来表示对象的ground truth集合,y^={y^i}i=1N\hat{y}=\{\hat{y}_i\}^N_{i=1}y^={y^i ...



