
Paper Reading: Earthformer
本文提出Earthformer,一个用于地球系统预测的时空Transformer。基于一个时空注意力块,名为立方体注意力。其想法是将数据分解成立方体,并并行应用立方体级的自注意力。
介绍
在本文中,我们提出了Earthformer,一个用于地球系统预测的时空Transformer。为了更好地探索时空注意力的设计,我们提出了立方体注意力,它是高效时空注意力的通用构建模块。其思路是将输入张量分解为不重叠的立方体,并并行应用立方体级的自注意力。
由于我们将 O(N2)O(N^2)O(N2) 自注意计算在在局部立方体上,因此整体复杂性大大降低。不同类型的相关关系可以通过不同的立方体分割方案来捕获。通过堆叠具有不同超参数的多个立方体注意力层,我们能够将以前提出的几个视频Transformer归纳为特殊情况,同时也提出了以前没有研究过的新注意力模式。
这种设计的一个局限性是缺乏一个本地立方体相互交流的机制。因此,我们引入了一个全局向量的集合,关注所有的局部立方体,从而收集系统的整体状态。通过关注全局向量,本地立方体可以掌握系统的总体动态,并相互分享信息。
模型
我们将地球系统的预测拟定为一个时 ...

Paper Reading: RepVGG
介绍
现在的ConvNets网络越来越复杂,尽管许多复杂的ConvNets比简单的提供更高的精度,但缺点也很明显:
多分支结构使得该模型难以实施和定制(需要保持特征图大小不变),减缓推理速度,降低内存利用率。
一些组件(例如Xception和MobileNets中的depth-wise卷积和ShuffleNets中的channel shuffle)增加了内存访问成本并缺乏对各种设备的支持。
由于影响推理速度的因素太多,浮点运算量(FLOPs)并不能准确反映实际速度。
本文中,我们提出了RepVGG,一种VGG风格的架构,其性能优于许多复杂的模型(图1)。RepVGG具有以下优点:
该模型有一个类似于VGG的普通拓扑结构,没有任何分支,这意味着每一层都将其唯一的前一层的输出作为输入,并将输出输入其唯一的后一层。
模型主体只使用了 3×33 \times 33×3 conv和ReLU。
具体的架构(包括具体的深度和层宽)被实例化,没有NAS、手动细化、复合缩放[,也没有其他重度设计。
由于多分支结构的好处都是易于训练,训练时用多分支结构来提升网络性能,而推理时,利用结构重参数化, ...
Coding: Python 列表推导式骚操作
移动 0
原题
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
标准方法
https://blog.csdn.net/weixin_38997425/article/details/
一个快指针与一个慢指针,慢指针找到0后,等待快指针找到第一个不为0的数,两者调换
1234567891011121314151617def moveZeroes(nums: list)->list: slow, fast = 0, 0 while slow < len(nums): if nums[slow] == 0: fast = slow + 1 while fast < len(nums): if nums[fast] != 0: temp = nums[slow] nums[slow] = num ...
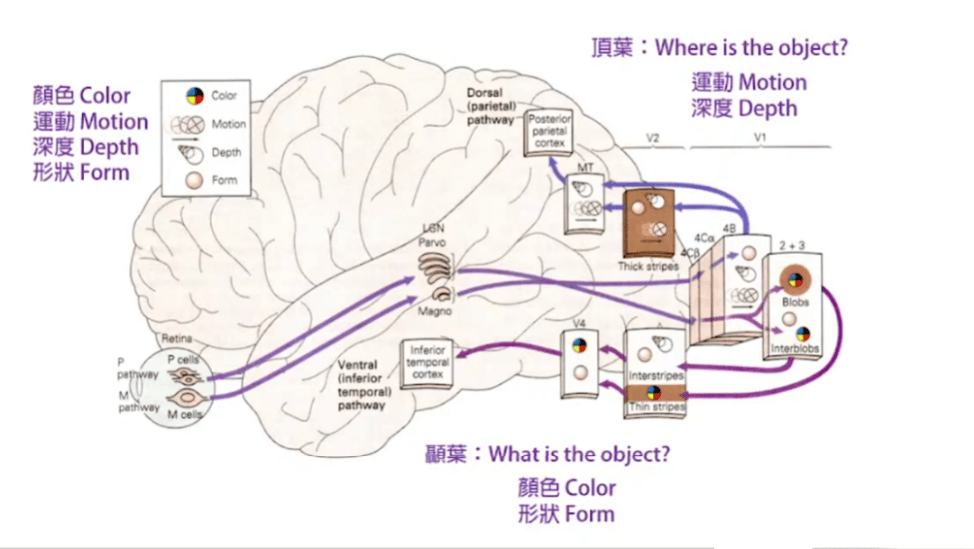
认知神经科学: 感觉与知觉(中)
信息的传递V1 -> V2 -> V3 -> IT:
V1(初级视觉皮质又称纹状皮层):对线条的方向产生反应。
V2 (属于纹外皮层):对错觉边缘(illusory contours)有反应,如下图
V3(属于纹外皮层):对形状与颜色有特点反应
IT(下颞叶细胞,Inferior temporal cells):对脸和复杂图案才有反应/
物体识别(Object recognition)
大脑有特别的脑区识别人脸(脸盲患者可以轻松辨别其他物体)。
大脑根据不同形状特征和外观特征进行编码。
与其他物体不同,如果脸部颠倒,无法正常辨识是谁。
物盲
物盲看到一个物体,无法辨别物体的功能,但是拿起要是,就能正常理解(记忆中存在概念,视觉上无法辨识)
物盲无法以功能性做配对。
物盲者与脸盲者受损的脑区不同,物盲可以识别出脸型。
色彩视觉
颜色所给予的信息没有明暗多。
完形心理学
不同的视觉特征会互相影响,颜色可以增强深度的判断,颜色对明暗的判断有影响等。
大脑有预设的观点解读世界:
相近的点放在一起。3
相似的放在一起,对垂直的线敏感,而对斜 ...

Paper Reading: Distilling the Knowledge in a Neural Network
知识蒸馏一直以为是啥高大上的东西,原来就是用大模型的输出作为label,训练小模型。
介绍
在大规模机器学习中,训练阶段与部署阶段的要求非常不同:训练时可以使用大量的计算资源,而部署阶段往往对延迟和计算资源有更严格的要求。
我们应该训练庞大的模型使更容易从数据中提取特征,一旦繁琐的模型被训练出来,我们就可以使用我们称之为“蒸馏”的训练方式,将知识从繁琐的模型转移到更适合部署的小模型上。
如果将模型的参数视为“知识”,很难看到如何将其从一种模型结构迁移到另一种不同的模型结构上。另一种更抽象的“知识”,是如何将输入映射到输出,这使它摆脱了任何特定的实例化。
分类模型即使目标是最大化正确答案的平均对数概率,但模型同样也会对错误的类别给予概率,即使这些概率非常小,其中一些也比其他的大很多。错误答案的相对概率告诉我们很多关于这个繁琐的模型如何倾向于归纳,其中也包含了更多的信息(知识)(如,一辆宝马车的图像,可能只有很小的几率被误认为是一辆垃圾车,但这种错误的概率仍然比把它误认为是胡萝卜的概率高很多倍。)
将繁琐模型的泛化能力(知识)转移到小模型的一个显然的方法是将繁琐模型产生的每个类概率作为“ ...
认知神经科学: 感觉与知觉(上)
https://www.bilibili.com/video/BV1gh411b7nU
眼球
视网膜
视网膜最后方,有两种感光细胞(Photoreceptor):
锥细胞(Cones):颜色感强,明亮环境视觉
杆细胞(Rods):感光度强,昏暗环境视觉
不同感光细胞对颜色的敏感度也不同
视网膜前方,有处理视觉信息的不感光细胞:
神经节细胞(Ganglion cell):处理视觉信息
视神经(optic nerve fibers)
眼球正中央存在没有血管,感光细胞最密的中央凹(fovea),此处不存在不感光细胞,是视野最清楚的地方。
中央凹只有视锥细胞,且密度远大于其他地方——解析度高,但是感光能力弱。
由于视神经与血管离开眼球,所以存在视觉盲点。(无脊椎动物感光细胞在前方,所以没有视觉盲点)。
在视觉盲点上,不会收到任何光学信号,神经系统会根据上下文自动生成(背景色,规则图像等)。
微动
眼球会有不自主的细微动作,只有专注一会才会停止,因为如果太久不“更新”感光细胞,其会产生“适应”的效果(对颜色感减弱等),同时能增加一定视觉能力,即看清周围信息。
凝视点
看 ...

Paper Reading: Bridging the Gap between Object and Image-level Representations for Open-Vocabulary Detection
介绍
通过图像水平监督(ILS)或使用ILS学习的预训练模型扩大词汇量的主要挑战之一是区域和图像层面线索之间固有的不匹配。例如,现有的OVD模型[2104.13921]中使用的预训练的CLIP嵌入在定位物体区域方面表现不佳,因为CLIP模型是用全比例图像训练的。使用标题描述或图像级别的标签对图像进行弱监督,并不能传达精确的以物体为中心的信息。
在本文中,我们打算在OVD管线中弥合以物体和图像为中心的表述之间的差距,我们提出通过预训练的多模态vision transformer(ViT)来利用高质量的类无关和类特定的对象建议[8]。类无关的对象建议被用来提取CLIP视觉嵌入中的区域特定信息,使其适用于局部对象。特定类别的建议集使我们能够在视觉上找到更大的词汇量,从而有助于对新类别的归纳。
接下来,最后一个重要的问题是如何使视觉语言(VL)映射能够适应以物体为中心的局部信息。为此,我们引入了一个以区域为条件的权重转移过程,将图像和区域的视觉语言映射紧密联系在一起。简而言之,所提出的方法将图像、区域和语言表征联系起来,以更好地概括新的开放词汇对象。
主要贡献
本文提出了基于区域的知识 ...

Paper Reading: MAE
简介
Masked Autoencoders(MAE)是用于计算机视觉中的自监督方法。MAE的方法非常简单:我们随机遮住输入图像的一些patch然后重建缺失的像素。
MAE基于两个架构:
我们开发了一个非对称编码器-解码器架构,编码器只在可见patch子集上计算(不计算被遮住的patch以节省时间),以及一个轻量级解码器,该解码器根据潜在表示和掩码token重建原始图像。
我们发现高比例的遮盖输入图像(如 75%75\%75%)会产生意义非凡的自监督任务,展现了很强的迁移性能。
结合这两种设计使我们能够有效地训练大型模型:我们加速训练3倍以上,并提高了准确性。
对数据的需求已经在NLP中通过自监督的预训练得到了成功的解决。这些解决方案基于GPT中的自回归语言建模和BERT中的Masked Autoencoders,在概念上很简单:它们删除了一部分数据并学习预测删除的内容。Masked Autoencoders的想法,是一种更普遍的去噪自动编码器的形式,很自然,也适用于计算机视觉中。但视觉中的自动编码方法的进展却落后于NLP,原因是:
结构差异,NLP中是Transformer ...

Paper Reading: DALL-E 2
介绍
像CLIP这样的对比学习模型可以学习稳健的图像表征,这些表征可以捕捉到语义和风格。为了利用这些表征来生成图像,我们提出了一个两阶段的模型:给定文本生成图像特征,称为prior(在这里训练完的CLIP所产生的图像特征作为ground truth),以及以图像嵌入为条件生成图像的解码器(均使用扩散模型)。
我们表明,显示的生成图像特征可以提高生成图像的多样性,而在逼真度和(标题)相似度方面没有什么损失。解码器基于给定的图像特征所生成的图片在风格上与语义相近,但是在特征中未包含的不必要的细节有所不同。
通过CLIP作为桥梁,能够达到通过文本直接对图像进行编辑的功能,并且是zero-shot的。
模型的选择
CLIP:通过简单的对比学习,就能学习到稳健的特征(例如对于分布偏移)。且拥有特别好的zero-shot能力。
扩散模型:在图像生成领域都达到了SOTA。是一个概率分布模型,多样性极佳,且经过优化(例如guidance technique)在保真度上也可以和GAN不相上下。
方法
如上图,虚线上方的是一个CLIP模型(文本编码器得到一个文本特征,图像编码器得到一个图像特征 ...
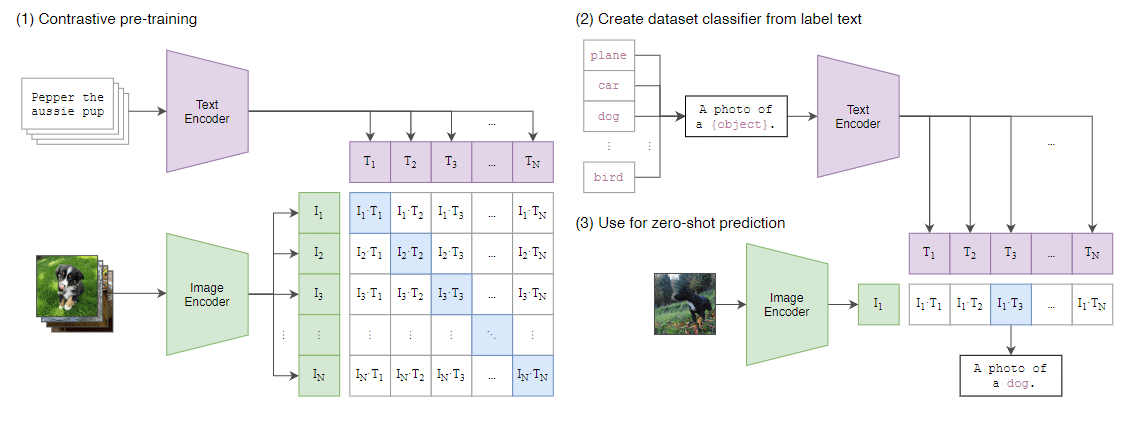
Paper Reading: CLIP
介绍
目前最先进的计算机视觉系统都是被训练来预测一组固定的预定物体类别。这大大限制了其通用性和可用性。
本文名为 Contrastive Language-image Pre-training(CLIP)方法直接从图像的原始文本中学习,预测哪个标题与哪个图像相配这一简单的预训练任务,是一种高效且可扩展的方式,且可以利用更广泛的数据来源,而无需人工标注。
本文不预先定义标签类别,直接利用从互联网爬取的4亿个图文对进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉。
方法
CLIP联合训练一个图像编码器与一个文本编码器,以预测一批图文正确配对。由于数据集足够大,图像数据增强只用了随机大小和随机宽高比的裁剪。
本文从网络爬取了 4 亿对图文数据集,称为 WebImageText(WIT),预训练时,使用 NNN 个图文对的超大batch,将batch中匹配的 NNN 个图文对作为正样本,而不匹配的 N2−NN^2 - NN2−N 个图文对作为负样本。正样本的两个编码器输出的特征的cosine similarity尽可能大,而负样本的尽可能小。如图所示。
在测试中使用pro ...



