永久关闭WIN10升级WIN11提醒
停止windows更新服务
打开 windows service管理器。
找到 Windows Update 服务
修改常规-启动类型为禁用,恢复-第一次失败为无操作,然后点击常规-停止停止服务,点击应用退出。
删除本地更新文件缓存
删除C:\$WINDOWS.~BT下所有文件(ps. 为隐藏文件夹,且需要系统权限)
重启即可。

Paper Reading: ViLBERT
本文提出了一个学习与任务无关的VLP模型,将BERT拓展到一个多模态的双流模型。通过co-atten进行不同模态的信息交互。
在大型的自动收集的数据集上预训练,可以容易的迁移到多种下游任务(MLM,VLM,MVM)。
将视觉基础(visual grounding)作为一种可预训练和迁移的能力。
介绍
VLP任务没有一个统一的方法提升不同模态的融合能力,通常先分别预训练语言和视觉模型,再通过微调学习文本与图像之间的grounding,通过这种方法学到的grounding并不可靠,如果数据量小,或存在大量噪音,那么模型的泛化能力会很差。
在单模态上拥有完美的模型,但无法在两个模态之间学习到联系,在下游任务中也没有什么用。因此,本文开发一个通用的visual grounding模型,在预训练中可以学习视觉与语言的联系,并在广泛的视觉和语言任务中利用它们——也就是说,我们寻求对visual grounding进行预训练。
为了学习视觉-语言的联合表征,本文使用多个代理任务(对图像进行着色或重建文本中的被屏蔽的词),以无监督的方式从大量没有标签的数据中学习丰富的语义和结构信息。本文使用一个视觉 ...
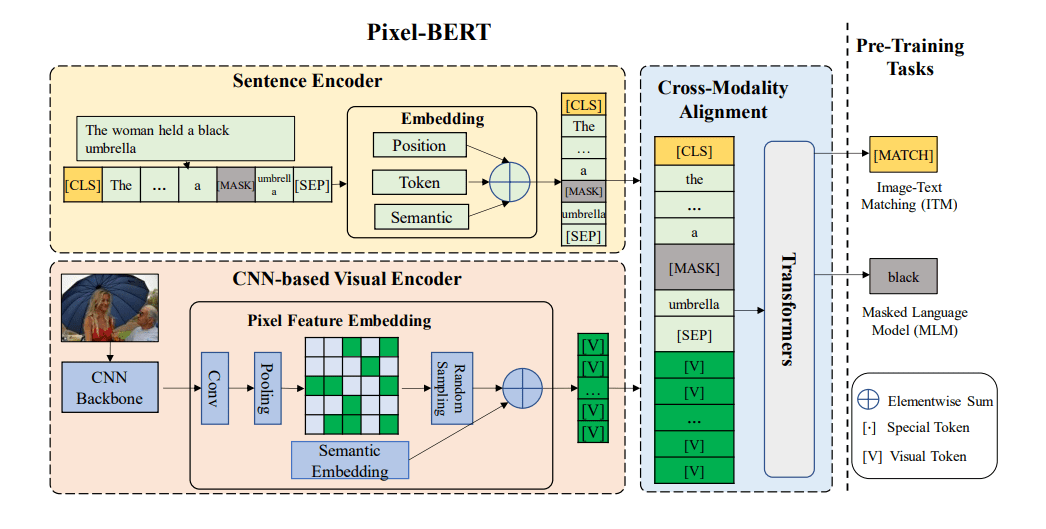
Paper Reading: Pixel-BERT
提出一个全新的可以端到端学习的模型Pixel-BERT,不基于区域的图像特征,将图片像素与文本对齐,克服区域特征的语义标签与语言语义之间的不平很,在图像与文本之间建立更加准确的联系。
介绍
基于区域的特征是为特定任务设计的,与语言理解的信息存在差距,同时特征的表示能力受限于训练时的给定种类,且边界框的背景会带来噪声信息,丢失目标的状态、对象之间的空间关系等。
因此本文提出Pixel-BERT,学习将图像像素与文本对齐。Pixel-BERT由三部分组成:
用于视觉特征提取的CNN(例如ResNet)
和BERT训练时方法一致的文本嵌入。
用于融合视觉模态和语言模态的Transformer
对于预训练与先前的模式相同:
文本掩码重建(MLM)
图文配对(ITM)
同时本文也提出了新的随机像素采样机制,以提高视觉模态上的鲁棒性。
方法
边界框特征包含嘈杂的背景,丢失了空间信息,为了充分利用视觉信息,本文的方法通过学习像素的视觉嵌入来完成文本-视觉任务。
文本特征嵌入
如BERT的方式一致,将句子分割为单词,使用WordPiece将每个单词标记为token,使用一个嵌入矩阵将每 ...
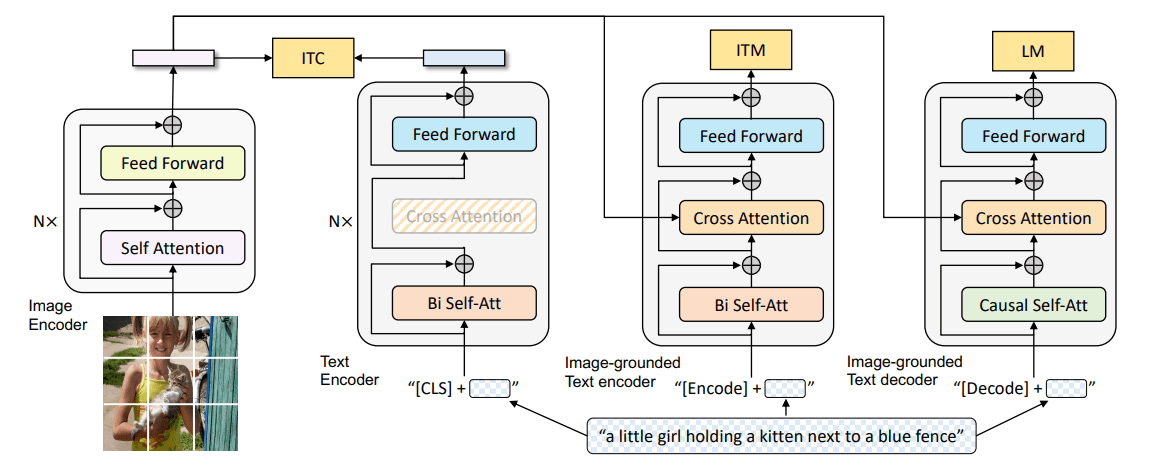
Paper Reading: BLIP
本文提出了一个新的VLP框架,BLIP:
能够同时胜任理解基于理解的任务与需要生成的任务。
通过引导字幕有效的利用来自网络的存在噪声的数据。使用字幕员生成合成字幕,过滤器删除了嘈杂的字幕。
在广泛的视觉语言任务上取得了SOTA如图像文本检索、图像字幕、VQA。
0-shot 的转移到视频语言任务也表现出强大的泛化能力。
简介
现有VLP方法的局限性:
模型角度:基于编码器的模型难以直接迁移到文本生成下游任务;基于编码器-解码器的模型难以用于图像文本检索任务。
数据角度:从互联网上收集的数据存在大量噪声,是次优的。
为此,本文提出一个新的VLP框架BLIP,胜任更广泛的下游任务:
多模态编码器-解码器混合(Multimodal mixture of Encoder-Decoder,MED):全新的网络架构,可以有效的多任务预训练和灵活的迁移学习。一个MED可以作为单个模态的编码器,或一个图像为基础的文本编码器或一个以图像为基础的文本解码器运行,该模型以三个视觉-语言目标进行训练:图像-文本对比学习、匹配、条件语言建模。
字幕过滤(CapFilt):新的数据增强方法。 将预训练 ...
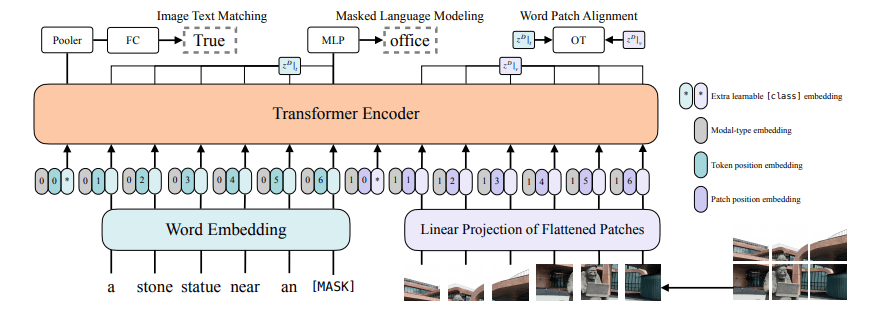
Paper Reading: ViLT
目前的VLP相比于文本更依赖于图像的特征提取过程:
效率低下,输入特征提取甚至比模态融合更复杂。
表达能力受限于预训练的视觉嵌入及其预定义的视觉词汇。
为此,本文提出ViLT,以统一的方式处理图像和文本信息:
ViLT是目前最简单的多模态(视觉-语言)模型。
在不使用区域特征和CNN的情况下,取得了合格的性能。
首次在VLP训练中,使用了全词遮罩和图像增强。
Introduction
VLP在预训练中,通常同时使用图文匹配和**重建文本(Mask)**两种方式,在下游任务上微调。
为了输入Transformer,原始图像输入需要被转换为另一种形式与文本一起输入,大部分工作在图像嵌入上使用一个预训练好的目标检测器,将密集的图像像素离散化(多个边缘框)。Pixel-BERT是一个例外,其使用一个预训练好的残差网络,直接将网络的特征输出作为一个离散的序列作为Transformer的输入,在速度上大大提高。但是目前仍然集中研究通过提升图像嵌入的性能以提高整体的性能而并未考虑速度,虽然可以将图像特征预先抽取,保存在本地硬盘上,但是对于现实任务,需要在线学习时仍然非常耗时。
为此,本 ...
宣传一个MC服务器
服务器名称
SakuraFall
支持版本
1.19
营利模式
公益服务器
游戏模式
生存
正版验证
True
最大在线人数
12
服务器类型
插件服,无需特定客户端
白名单
False
QQ 裙
465248621 (二次元浓度100%)
服务器IP
owo.nyakura.cc
服务器概况
世界结构
两个主世界及其对应下届,以及一个共享的末地。
生存世界(桜落坊),生存地狱。有苦力怕爆炸保护,放心建家。
资源世界(桜料坊),资源地狱
末地
指令
/town select 切换世界(桜落坊与桜料坊之间),切换要钱,切换过后可以一直免费/town tp传送到该世界。
/back 返回上一个地点,要钱。
/home 返回家,要钱。
/sethome 设置家(很贵,多设置一次倾家荡产)。
游戏模式
死亡掉落
没有领地插件,但是有/co i防熊,以及箱子锁
原版生存
钱很难搞,但是靠礼包前期可以活。
我家
主城往-z方向走1000格,坐标x:0 y:70 z:-1000,欢迎来玩。
截图
服务器主城
...
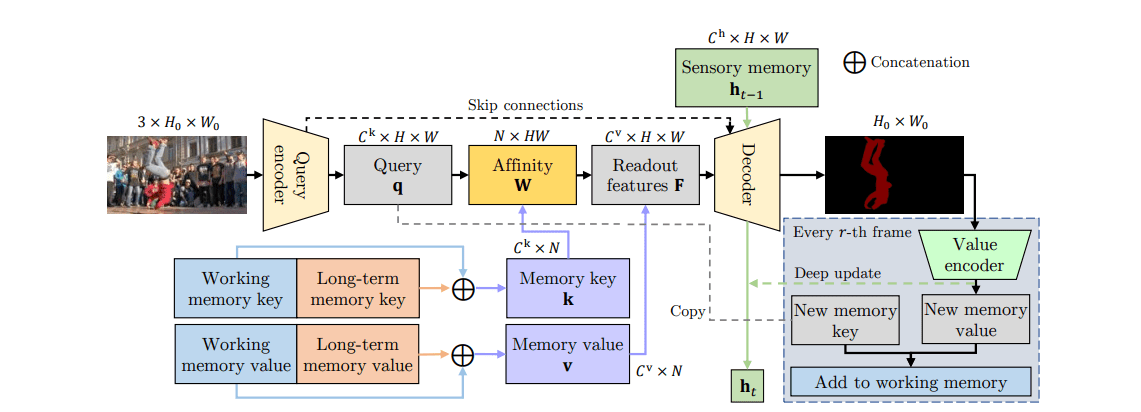
Paper Reading: XMem
本文提出了新的视屏对象分割架构 XMem,使用同一的特征记忆存储,包含多个独立但深度连接的记忆存储:
快速更新(每帧)的感官记忆。
高分辨率的工作记忆。
紧凑的持续长期记忆。
同时开发了一个记忆增强算法。
介绍
先前的SOTA精度高,但内存占用也高,不适合长视频。用于长视频的架构抛弃了一部分精度,效果不佳——这种性能与内存消耗的不良联系时因为单一的功能的记忆。
我们提出一种统一的记忆架构,受 Atkinson–Shiffrin 记忆模型[Human Memory: A Proposed System and its Control Processes]的启发,该模型假设人类记忆由三个部分组成,XMem维护着三个独立但紧密连接的特征记忆存储:
快速更新的感官记忆:每帧更新一次。
高分辨率的工作记忆:存储大小固定,如果已满,则整合到长期记忆。
紧凑的持续长期记忆:在数千帧后,长期记忆也满时,丢弃过时的特征,以限制GPU内存使用量。
方法
概览
为了提高可读性,我们考虑单个目标对象。给定第一帧(图 2 左上角)的图像和目标对象掩码,XMem跟踪对象并为后续查询帧生成其掩码。
...
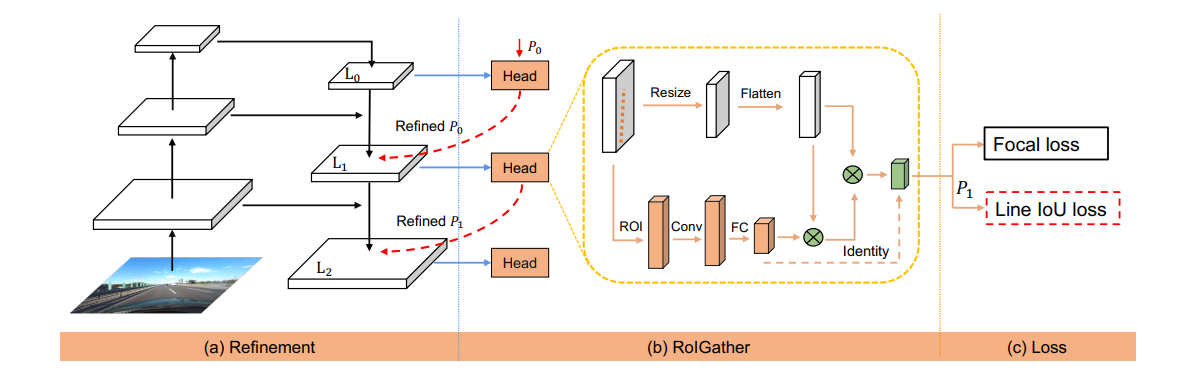
Paper Reading: CLRNet
一个新颖的网络结构 CLRNet,以充分利用不同层次的特征进行车道线检测。
ROIGather 通过收集全局上下文信息来进一步加强车道特征表示。
我们提出了为车道检测量身定做的 Line IoU(LIoU)损失,将车道作为一个整体进行回归,大大改善了性能。
SOTA
介绍
本文提出了一个新的框架,跨层细化网络(CLRNet),它充分地利用了低层次和高层次特征来进行车道检测。我们首先对高层次语义特征进行检测,以粗略地定位车道,然后,我们根据精细细节特征进行细化,以获得更精确的位置。对车道位置和特征提取进行逐渐细化,可获得高精度的检测结果。
为了解决车道非视觉证据的问题,我们引入了ROIGather,通过构建ROI车道特征与整个特征图之间的关系来捕获更多的全局上下文信息。
我们定义了车道线IoU,并提出Lane IoU(LIoU)损失,将车道作为一个整体单元进行回归。
方法
车道线的表示
车道被表示为一个等距的二维点的序列,P={(x1,y1),...,(xN,yN)}P = \{(x_1,y_1),...,(x_N,y_N)\}P={(x1,y1),...,(xN,yN ...
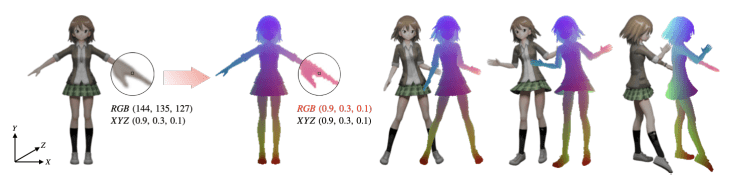
Paper Reading: CoNR
在动漫制作中绘制人物的不同姿势是一项重要而费时的任务。本文提出了写作神经渲染(CoNR)方法,从少量的角色姿势参考图中生成新的图像。动漫与显示不同,身体形状更多样,使得现实世界人类的通用身体模型(如SMPL)无法被采用。为此CoNR使用了一个紧凑的、容易获得的关键点编码,以避免在网络中使用统一的UV映射。我们收集了一个角色表数据集,包含超过700000张不同姿势的手绘和合成图像,以促进该领域的研究。
介绍
我们制定了姿势渲染任务。没有将角色表建模当作序列,因为序列存在排序问题,而是将其视为动态大小的集合,这也更符合动漫产业的既定惯例。探索前馈神经网络的协作推理方法,将字符表建模为一个动态大小的图像集。
在此基础上,我们开发了一个协作神经渲染(CoNR)模型。CoNR通过使用特征空间跨视图密集通信与warp,充分利用了所提供的一组参考图像中的信息。引入了专门为动漫人物设计的UDP(Ultra-Dense Pose)表示法。,这是一个易于构建的紧凑关键点,专门为动漫人物设计,以避免在管道中需要统一的UV纹理映射,它可以表现人物的精细细节,如兔耳、发型或服装,从而可以更好地艺术控制和调整所 ...
Coding: 使用 Yolo 的安全帽检测
由于 yolo 已经写好了训练测试等方法,所以我们主要的事情就是如何处理数据集
准备工作
Yolo
头盔检测数据集
用到的库
12345678910import osimport yaml # 用于配置 yolofrom shutil import copyfile # 复制文件import xml.dom.minidom as minidom # 处理 xml 格式的原始标签数据import numpyfrom sklearn.model_selection import train_test_splitfrom tqdm import tqdm
数据预处理
数据集中的类别
1classes = ['helmet','head','person']
我也不知道里面为什么会有几个person的标签。
处理锚框数据
将存储为左上角左边(xmin,ymin),右下角左边(xmax,ymax)格式的包围框转为,中心点(x,y)与高宽(w,h),并进行基于图片大小的归一化。
123456789101112131415 ...



