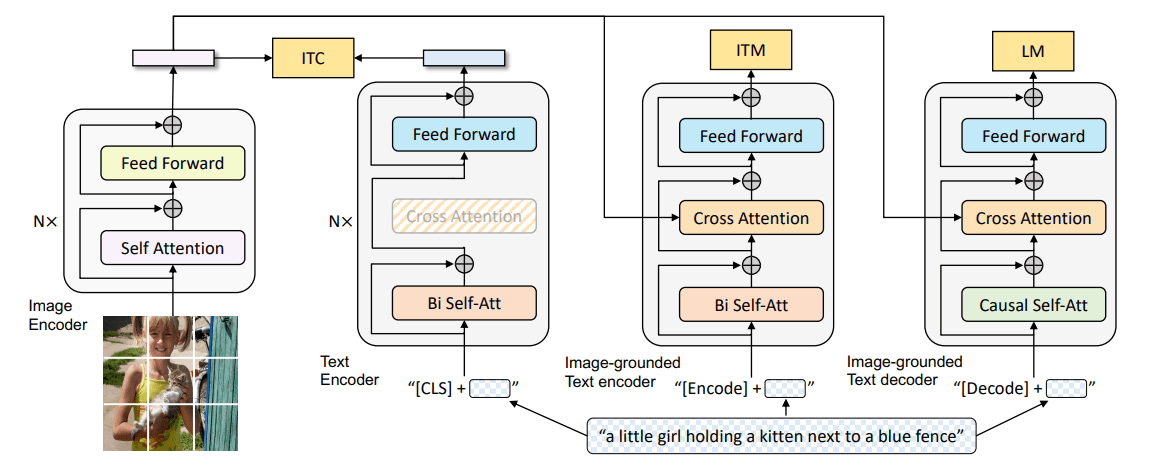
Paper Reading: Pre-trained Models for Natural Language Processing: A Survey
本文为NLP的PTM提供了一个整体的回顾。
- 语言表征学习
- 从多个角度对现有
PTM进行系统的分类, - 下游任务
- 未来研究的潜在方向
PTM - Pre-trained Models
背景
语言表征学习
在NLP中,一个好的表征应该捕获文本中的潜在语言规则和常识性知识(如词义,语法结构等)。
分布式表征(词向量):用低维的实值向量表述文字。向量的每个维度都没有相应意义。
词嵌入:有两种词嵌入非语境(non-contextual)与语境下(contextual)的词嵌入,后者代表其会根随词所在的语境而动态变化。

非语境词嵌入
通过查表(词数量 固定,嵌入向量维度 固定)的方式,将每个单词(或子词)映射到一个嵌入向量。
给定一个词表 中的单词 ,通过查表 映射到一个向量 ,其中 是超参数,即token嵌入(词嵌入)的维度。
这种嵌入无法捕获上下文信息,以对多义词进行建模,即不同语境中相同单词的嵌入向量总是相同的,即便表达的含义不同。
语境嵌入
给定文本,馈送到一个神经编码器,对于每个单词的输入得到一个语境嵌入(动态嵌入)。
给定文本 其中每个token 是一个单词或子词。
其中 是神经语境编码器,在下文中会介绍。 称作语境嵌入或动态嵌入。
神经语境嵌编码器

大多数可以分为两类:序列模型与非序列。
序列模型
按顺序捕捉一个词的局部语境。
- 卷积:通过卷积操作聚合临近的局部信息来捕获词的含义。
- 循环:如
LSTM与GRU,使用短时记忆捕捉单词的上下文表征。实践中使用双向循环以手机单词的双边信息,性能受到长期依赖性影响。
非序列模型
- 基于图的模型:用预先定义的词与词之间的树或图结构来学习上下文表示。如
TreeLSTM,GCN。和大程度上依赖专家知识与外部NLP工具。 - 自注意力机制模型:全连接自我注意模型的成功实例是
Transformer,它还需要其他补充其他模块,如位置嵌入、LayerNorm、残差连接和基于位置的前馈网络层。
总结
序列模型难以捕捉长距离的关系,但是容易被虚拟蓝。
自注意力模型可以直接建模句子中的任意两个词的关系,适合长距离依赖关系的建模,但是训练困难,需要大量数据,否则容易过拟合。
预训练的意义
大模型需要大数据集防止过拟合,数据注释成本昂贵。
大规模的无标签语料库容易构建,为了利用这些无标签数据,可以首先从这些数据中训练一个好的表示,然后将这些表示用于其他任务。
预训练的优势:
- 可以学习通用的语言表征。
- 更好的模型初始化参数,提供更好的泛化性能,加速目标任务的收敛。
- 可以避免小数据集的下游任务上的过拟合。
NLP的PTM简史
预训练然后对下游任务微调是学习深度神经网络的有效策略。
第一代PTM - 预训练的词嵌入
在未标记的数据上预训练词嵌入可大大改善许多NLP任务,但它们与上下文无关,且是由浅层模型训练的,且在下游任务上,整个模型的其余部分都需要从头开始学习。
e.g. NNLM、CBOW、SG、Word2Vec、GloVe
在同一时期,许多研究者试图将输入的句子编码为一个固定维度的向量表示,而不是每个标记的上下文表示。
e.g. Context2Vec、Skip-thought vector
第二代PTM - 预训练的语境编码器
在句子级别或更高级别上对神经编码器进行预训练,神经编码器的输出称为语境词嵌入,代表了取决于语境的词的语义。
e.g. ULMFiT、BERT、GPT

PTM概览
PTM之间的主要区别在于语境编码器的使用,与训练任务和用途。
预训练任务
通常,预训练任务应该具有挑战性,并且具有大量的训练数据。
-
监督学习(supervised learning,SL):基于由输入-输出对组成的训练数据,将输入映射到输出。
-
无监督学习(unsupervised learning,UL):是从未标记的数据中找到一些内在知识,例如聚类。
-
自监督学习(self-supervised learning)是监督学习和无监督学习的混合体,标签是自动生成的。
除了机器翻译以外,大多数监督任务的数据集不够大,
语言建模(Language Modeling,LM)
最常见的无监督任务。实践中,特质自回归LM或者单向LM。
给定文本序列 ,其联合概率可分解为:
其中 指序列开头的词语,上下文 可以通过神经编码器 建模
其中 是预测头。
掩码语言建模(Masked Language Modeling,MLM)
从输入句子中屏蔽一些token,然后训练模型通过其余token来预测屏蔽的token。
微调阶段不会出现掩码令牌,为了解决这个问题,在实践中的时间使用特殊的“MASK”token,的时间使用随机token, 时间使用原始token。
变体:
- 序列到序列 MLM(Sequence-to-Sequence MLM,Seq2Seq MLM):原始
MLM通常作为分类问题解决,Seq2Seq则使用序列到序列的方法预测被遮罩的输出。可以使 Seq2Seq 式的下游任务受益,例如问答、总结和机器翻译。 - 增强型 MLM(Enhanced Masked Language Modeling,E-MLM):多项研究提出了不同的MLM增强版本,如
RoBERTa的动态掩码,UniLM的单向、双向和序列到序列预测,XLM的并行双语句子对的串联MLM(TLM),SpanBERT的随机连续掩码和跨度边界目标(SBO)。Struct BERT引入的Span Order。
排序语言建模(Permuted Language Modeling,PLM)
输入序列随机排列的语言建模任务,排列是从所有可能的排列中随机抽取的。然后选择置换序列中的一些令牌作为目标,并根据其余令牌和目标的自然位置训练模型来预测这些目标。
去噪自动编码器(Denoising Autoencoder,DAE)
采用部分损坏的输入,恢复原始未失真的输入。一般使用特定语言的Seq2Seq模型。
噪声添加方式:
- Token Masking:随机选取
token,替换为“MASK”token。 - Token Deletion:从输入中随机删除一些词语。需要模型自己判断缺失输入的位置。
- Text Infilling:服从泊松分布()采样一系列文本片段替换为单独一个“MASK”
token,模型需要预测缺失片段的数量。 - Sentence Permutation:将文档拆分为句子打乱顺序。
- Document Rotation:随机选择一个
token并旋转文档,使其以该标记开头。模型需要确定文档的实际起始位置。
对比学习(Contrastive Learning ,CTL)
假设一些观察到的文本对 在语义上比随机抽样的文本对 更相似。一个评分函数 学习以最小化目标函数:
评分函数 通常计算为可学习的神经编码器两种方式 或
CTL通常具有较低的计算复杂性。
最近提出的CTL任务:
-
Deep InfoMax(DIM):由视觉任务而来,目标是 得到比 更高的分数,其中 表示 到 的n-gram片段, 表示带有掩码的片段 表示随机采样的片段。
-
Replaced Token Detection(RTD):被替换的标记检测,根据上下文预测一个标记是否被替换。
-
Next Sentence Prediction(NSP):训练模型以区分两个输入句子是否为训练语料库中的连续段。
-
Sentence Order Prediction(SOP):如
NSP一样,但是使用同一文档中的两个连续片段作为正面例子,而相同的两个连续片段,但其顺序被调换为负面例子。
预训练扩展
Knowledge-Enriched PTMs
PTM通常从通用的大规模文本语料库学习通用的语言表征,缺乏特定领域的知识。将外部知识库中的领域知识纳入PTM被证明是有效的,这些知识包括语言学、语义学、常识、事实、到特定领域的知识。
多语言和特定语言的 PTM
多语言PTM
- 跨语言理解(Cross-Lingual Language Understanding,XLU):早期工作聚焦在学习多语言词嵌入上,通常(弱)对齐不同语言的文本到一个语义空间。
- 跨语言语言生成(Cross-Lingual Language Generation):多语言生成是一种从输入语言生成不同语言文本的任务,如机器翻译和跨语言的抽象概括。与多语言分类不同,通常需要对编码器和解码器共同进行预训练,而不是只关注编码器。
特定语言PTM
尽管多语言的PTM在许多语言上表现良好,但最近的工作表明,在单一语言上训练的PTM明显优于多语言结果
多模态PTM
-
视频-文本 PTM:视频分别由基于
CNN的编码器和现成的语音识别技术进行预处理。在处理过的数据上训练一个Transformer编码器,以学习视觉-语言表征,用于视频字幕等下游任务。 -
图像-文本 PTM:除了视频语言预训练的方法外,还有一些工作在图像-文本对上引入了PTM,目的是为了适应下游任务,如视觉问题回答(VQA)和视觉常识推理(VCR)。
-
语音-文本 PTM
模型压缩
模型剪枝
去除网络的一部分(如权重、神经元、层、通道、注意头),从而达到减少模型大小和加快推理时间的效果。
Quantization
将高精度的参数压缩到低精度,通常需要兼容的硬件。
参数共享
虽然参数数量大大减少,但一般来说,参数共享并不能提高推理阶段的计算效率。
知识蒸馏
一个称为学生模型的小模型被训练来重现一个称为教师模型的大模型的行为。
模块更换
用更紧凑的替代物替换原始PTM的大模块.
早退
它允许模型在一个岔路口提前退出而不是通过整个模型。要执行的层数是以输入为条件的。