Paper Reading: CLRNet
- 一个新颖的网络结构
CLRNet,以充分利用不同层次的特征进行车道线检测。 ROIGather通过收集全局上下文信息来进一步加强车道特征表示。- 我们提出了为车道检测量身定做的
Line IoU(LIoU)损失,将车道作为一个整体进行回归,大大改善了性能。 - SOTA
介绍
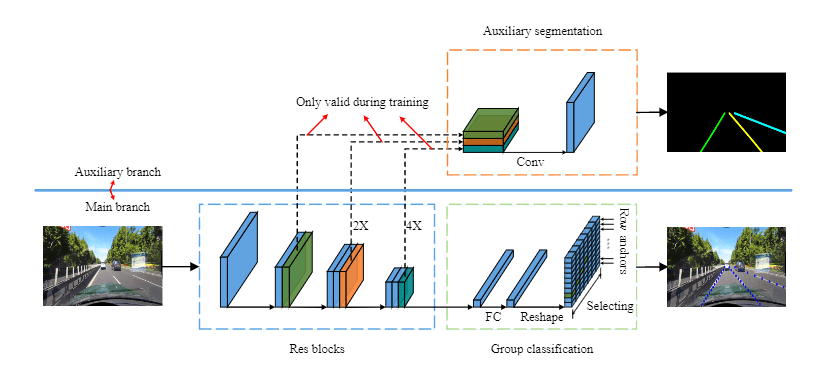
本文提出了一个新的框架,跨层细化网络(CLRNet),它充分地利用了低层次和高层次特征来进行车道检测。我们首先对高层次语义特征进行检测,以粗略地定位车道,然后,我们根据精细细节特征进行细化,以获得更精确的位置。对车道位置和特征提取进行逐渐细化,可获得高精度的检测结果。
为了解决车道非视觉证据的问题,我们引入了ROIGather,通过构建ROI车道特征与整个特征图之间的关系来捕获更多的全局上下文信息。
我们定义了车道线IoU,并提出Lane IoU(LIoU)损失,将车道作为一个整体单元进行回归。
方法
车道线的表示
车道被表示为一个等距的二维点的序列,,点的 坐标在图像中被垂直地平均采样(即等距)。 其中 是图像高度。因此, 坐标与其对应的 坐标相关,我们称这种表示为车道先验。每个车道先验将由网络预测,由四个部分组成:
- 前景和背景概率
- 车道先验的长度
- 车道线的起始点和车道先验的 轴之间的角度( 和 )。
- 个偏移量,即预测和其
ground truth之间的水平距离。
跨层细化

Motivation
深层高级特征有助于利用更多有用的上下文信息(区分车道和关键点),精细细节特征有助于检测具有高定位精度的车道。
受 Cascade RCNN[1712.00726]的启发,我们可以将车道对象分配到所有级别,并按顺序检测车道。特别是,我们可以用高级特征检测车道,粗略地定位车道。 在检测到的车道的基础上,我们可以用更详细的特征来完善它们。
Refinement structure
我们的目标是利用CNN的金字塔式特征层次,其语义从低到高,并建立一个贯穿高层语义的特征金字塔。
我们以ResNet做为骨干网络,用 来表示FPN产生的特征级别。如[图1]所示,我们的跨层细化从最高层 开始,逐渐接近 。我们用 来表示相应的细化。 然后我们可以建立一个细化的序列
其中 ,是细化的总次数。对于第一层 , 是随机分布在图像平面上的。
细化 以 为输入,得到ROI车道特征,然后经过两个FC层,得到细化后的参数 。
ROIGather
Motivation
使用长距离的依赖关系,在没有视觉信息的车道线上的性能可以得到改善。我们沿着车道先验添加卷积。这样一来,车道先验中的每个像素都可以收集附近像素的信息,而视觉信息少(被遮挡、反光)的部分可以从这些信息中得到加强。此外,我们在车道先验的特征和整个特征图之间建立关系。因此,它可以利用更多的上下文信息来学习更好的特征表示。
ROIGather模块
ROIGather将特征图和车道先验作为输入,每个车道先验有 个点。对于每个车道先验,我们按照 来得到车道先验的ROI特征 。与边界盒的 不同,我们从车道先验中统一取样 个点,并使用双线性插值来计算这些位置的输入特征的精确值。对于 、 的ROI特征,我们将前几层的ROI特征串联起来以增强特征表示。对提取的ROI特征进行卷积,以收集每个车道像素的附近特征。为了节省内存,我们使用全连接来进一步提取车道先验特征()。该特征图被调整为 ,并被平坦化为 。
为了收集车道先验特征的全局上下文,我们首先计算ROI车道先验特征(Xp)和全局特征图(Xf)之间的注意[27]矩阵W,它被写成
其中 是一个归一化的函数 。聚合的特征写成
输出 反映了 对 的奖励.最后,我们把输出加到原始输入 上
Line LoU loss

Motivation
与距离损失相比,交并比(IoU)可以将车道先验作为一个整体单位进行回归,它是为评价指标量身定做的。在我们的工作中,我们得出了一种简单有效的算法来计算Lane IoU(LIoU)损失。
Formula
我们从线段IoU的定义开始介绍线段IoU的损失,它是两个线段之间的相互交并比。对于预测车道上的每个点,如图3所示,我们首先将其 以一个半径 扩展为一个线段。然后,可以计算出扩展后的线段和它的ground truth之间的IoU,它被写成:
其中 是 的扩展点, 是 ground truth,注意, 是负数,这可以使其在非重叠线段的情况下进行优化是可行的。
那么LIoU可以被认为是无限线点的组合。为了简化表达式并使其易于计算,我们将其转化为离散形式。
那么LIoU损失被定义为
其中 ,当两条线完全重叠时,则 ,当两条线相距较远时, 收敛为。
Training and Infercence Details
Positive samples selection.
在训练过程中,每个ground truth道被动态地分配给一个或多个预测车道作为正样本。特别是,我们首先根据分配成本对预测车道进行排序,其定义为:
其中 是预测和标签之间的focal loss[1708.02002], 是预测的车道和ground truth之间的相似性成本。由所有车道点的平均像素距离,其实坐标距离,夹角插值组成,它们都被归一化为 。每个ground truth车道都被分配了一个基于 的预测车道的动态数(top-k)。
Training Loss
是focal loss,\mathcal{L}_{xytl}$ 是 smooth- 损失。