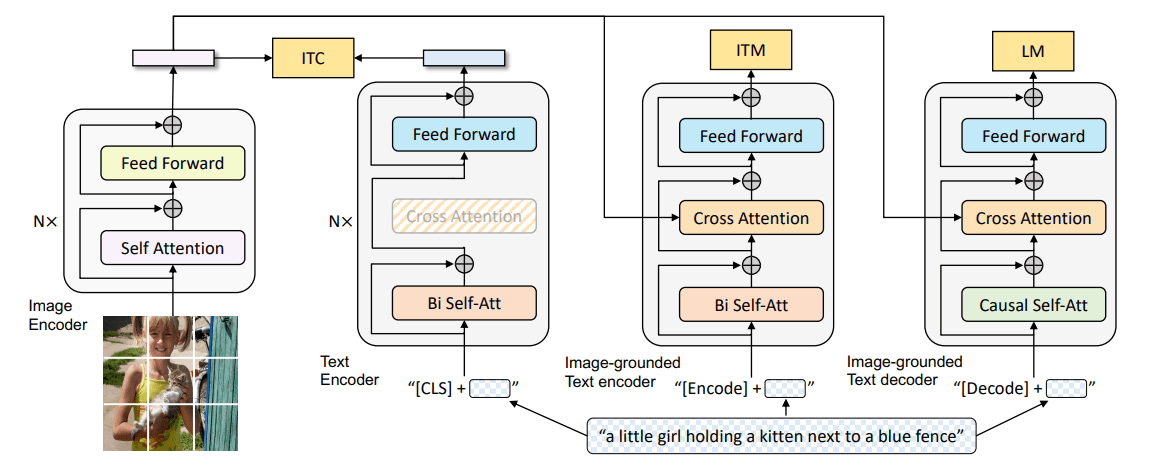
Paper Reading: CoNR
在动漫制作中绘制人物的不同姿势是一项重要而费时的任务。本文提出了写作神经渲染(CoNR)方法,从少量的角色姿势参考图中生成新的图像。动漫与显示不同,身体形状更多样,使得现实世界人类的通用身体模型(如SMPL)无法被采用。为此CoNR使用了一个紧凑的、容易获得的关键点编码,以避免在网络中使用统一的UV映射。我们收集了一个角色表数据集,包含超过700000张不同姿势的手绘和合成图像,以促进该领域的研究。
介绍
我们制定了姿势渲染任务。没有将角色表建模当作序列,因为序列存在排序问题,而是将其视为动态大小的集合,这也更符合动漫产业的既定惯例。探索前馈神经网络的协作推理方法,将字符表建模为一个动态大小的图像集。
在此基础上,我们开发了一个协作神经渲染(CoNR)模型。CoNR通过使用特征空间跨视图密集通信与warp,充分利用了所提供的一组参考图像中的信息。引入了专门为动漫人物设计的UDP(Ultra-Dense Pose)表示法。,这是一个易于构建的紧凑关键点,专门为动漫人物设计,以避免在管道中需要统一的UV纹理映射,它可以表现人物的精细细节,如兔耳、发型或服装,从而可以更好地艺术控制和调整所需的姿势,达到动漫制作的目的。
它也可以很容易地用现有的计算机图形管道生成,允许广泛的互动应用,如基于动画的游戏或虚拟助手。
并建立了一个包含各种姿势的大型人物表数据集。在这个数据集上训练,CoNR在手绘图像和合成图像上都取得了令人印象深刻的结果。
方法
制定任务
将一个角色表 整体视为输入样本,忽略参考图像 的顺序,为了向模型提供渲染指令,在输入中还需要一个目标姿势表示 。
任务可以被表述为将输入样本 映射到目标图像 ,该图像遵循所需的目标姿势 。
复杂的姿势、动作或人物可能需要比其他更多的 中的引用集合。因此,也应该允许有一个动态大小的 。
构建角色表
为了解决3.1中的任务,我们利用了受PointNet [1612.00593] 和Equivariant-SFM [2104.06703] 启发的卷积神经网络协作推理(CINN)。
在CINN中,一组中的多个图像被整体定义为一个单一的输入样本。多幅图像可以按任意顺序输入同一CNN的多个副本(权重是共享的),以获得相应的推理结果。并对多个副本中对所有相应块的输出进行特征平均化,我们得到一个由动态数量的子网络组成的网络。
在这样的网络上进行协作推理时,一组中的 个参考图像被分别送入 个权重共享的子网络。如下图所示,这些子网络形成了一个全连接的图,这样,一个子网络的每个区块都会将其部分输出分享给所有其他子网络中相应的连续块。为了进一步调节每个块后发送的跨视图信息,我们对信息进行加权平均,其中权重是由CNN预测的,并根据视图的数量进行归一化。
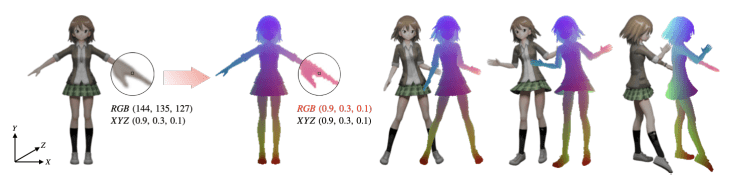
Ultra-Dense Pose
我们提出了UDP,一种专门为动漫人物设计的紧凑的关键点表示法。UDP通过将二维视口坐标映射到特征向量来指定角色的姿势,特征向量是连续和一致地编码身体表面的3元组浮点数。这样,一个UDP可以表示为一个彩色图像 ,其像素对应于关键点 。UDP图像中的非人物区域被简单地掩盖了。它可以更好地兼容更广泛的动漫身体形状,并能更好地对身体细节(如服装运动)进行艺术控制。
以站在世界中心的三维网格为例,为了构建UDP,我们用一个关键点覆盖每个顶点的rgb颜色,这个地标就是当前的世界坐标。 当动漫身体改变姿势时,网格上的顶点可能会移动到世界坐标系中的一个新位置,但相应身体部位的地标将保持不变,在图中显示为相同的颜色。
我们将修改后的网格转换成摄像机视口下的二维图像。由此产生的UDP表示是一个 形状的图像,四个通道包括关键点位置编码,与指示像素是否在身体上的占用,四个值范围在 到 之间。
UDP是一种详细的三维姿势表示,因为动漫身体上的每一个微小的表面,不管是头发还是衣服,都可以自动分配一个独特的编码,且不需要手工制作注释。UDP是一种广泛兼容的姿势表示法,具有可接受的交换性,因为具有类似身体形状的动漫人物也会得到一致的伪色的出装。UDP的作用是描述人体的局部三维形状,它可以为下游任务提供额外的几何信息。
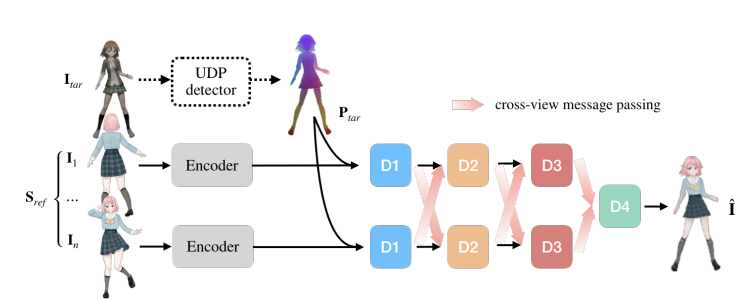
协作性神经渲染 CoNR
CoNR由一个渲染器和一个可选的UDP检测器组成,CoNR生成所需姿势的角色图像。将目标姿势的UDP表示 和角色表 作为输入。生成一个以上姿势时,我们输入不同的 UDP 并保持相同的参考角色表。
渲染
在U-Net的基础上,我们应用了以下修改。
- 为了实现对视频的高效推理,我们从编码器删除了
UDP输入,而是将UDP输入用临近采样法重新缩放后串联到从编码器到解码器的每个跳层通道,如图所示。这使我们能够检查来自编码器的评估结果,当对视频中的多个目标UDP进行推理时,这些结果可以被重新使用。 - 我们在每个解码块中使用两个额外的通道来生成一个
flow-field,并对该块的其他输出特征进行网格采样,以增强CNN的长距离查询能力。 - 我们将
CINN方法应用于网络的解码器。我们将原始的上采样输出特征通道分成两半,一个作为远程分支,另一个为本地分支。首先只对远程分支进行warp。然后对所有子网络的远程分支的输出特征进行平均,并传递到下一个区块。本地分支保持不变。本地分支的输出和前一个块的远程分支的输出与编码器的输出相连接,并送入下一个块。最后一个解码器块将收集所有子网络中先前所有解码器块的平均输出特征,并将其解码为最终的输出。
UDP检测器
为了准备目标姿势的UDP表示法 ,我们使用一个简单的U-Net,包括一个ResNet-50编码器和一个带有5个残差块的解码器,从 图像 中检测它,UDP检测器对目标 进行评估,以服从四通道UDP表示。
检测器可以在合成的数据集上独立训练,也可以以端到端的方式与渲染器联合训练。在第二种情况下,检测器可以向渲染器提供关于UDP的增量,当检测器收敛时,增量会逐渐减少。为了进一步减少模型的内存占用,我们可以在UDP检测器的编码器中与渲染器的编码器共享ResNet-50骨干网的权重。