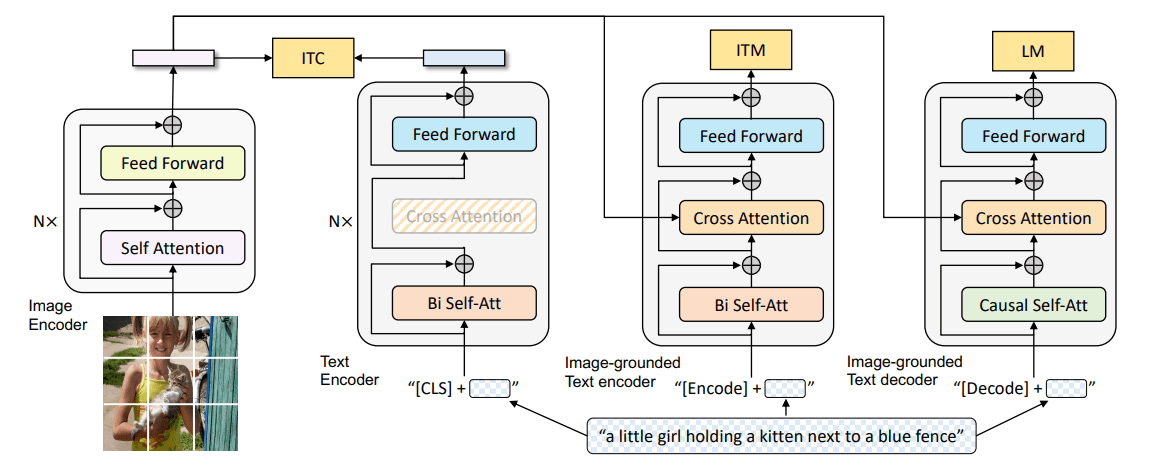
Paper Reading: Distilling the Knowledge in a Neural Network
知识蒸馏一直以为是啥高大上的东西,原来就是用大模型的输出作为label,训练小模型。
介绍
在大规模机器学习中,训练阶段与部署阶段的要求非常不同:训练时可以使用大量的计算资源,而部署阶段往往对延迟和计算资源有更严格的要求。
我们应该训练庞大的模型使更容易从数据中提取特征,一旦繁琐的模型被训练出来,我们就可以使用我们称之为“蒸馏”的训练方式,将知识从繁琐的模型转移到更适合部署的小模型上。
如果将模型的参数视为“知识”,很难看到如何将其从一种模型结构迁移到另一种不同的模型结构上。另一种更抽象的“知识”,是如何将输入映射到输出,这使它摆脱了任何特定的实例化。
分类模型即使目标是最大化正确答案的平均对数概率,但模型同样也会对错误的类别给予概率,即使这些概率非常小,其中一些也比其他的大很多。错误答案的相对概率告诉我们很多关于这个繁琐的模型如何倾向于归纳,其中也包含了更多的信息(知识)(如,一辆宝马车的图像,可能只有很小的几率被误认为是一辆垃圾车,但这种错误的概率仍然比把它误认为是胡萝卜的概率高很多倍。)
将繁琐模型的泛化能力(知识)转移到小模型的一个显然的方法是将繁琐模型产生的每个类概率作为“软目标”(训练集的onehot编码则称为硬目标)来训练小模型。
对于简单的任务繁琐模型通常会给出低熵的正确答案,大部分类别的置信度非常小,如 这样几乎为 的值,这导致在知识转移的时候对交叉熵损失的影响很小,我们提出了一种方案称为“蒸馏”,就是提高最终softmax的“温度(temperature)”使繁琐模型产生一套合适的软目标。然后我们训练小模型时,使用同样的温度拟合这些软目标。
虽然转移数据集可以完全由未标记的数据组成,但是我们发现,使用原始训练集效果很好,特别是如果我们在目标函数中加入一个小项,鼓励小模型预测真实目标同时也匹配繁琐模型所提供的软目标。 通常情况下,小模型不能完全匹配软目标,在正确答案的方向上犯错,结果是有帮助的。
蒸馏
神经网络通常通过使用一个softmax层来产生类别概率,加入温度 (默认为 ),高温度产生一个更柔和的类上的概率分布,
在蒸馏时,使用转移数据集时,会设置一个较高的温度,但在它被训练后,它使用的温度为 。
当所有或部分转移集的正确标签都是已知的时候,我们的方法通过同时训练蒸馏模型来产生硬标签而得到明显的改善。简单地使用两个不同目标函数的加权平均。
- 第一个目标函数是与软目标的交叉熵,这个交叉熵的计算方法是在蒸馏模型中使用高温的
softmax,就像从繁琐的模型中生成软目标时一样。 - 第二个目标函数是与硬标签的交叉熵。使用温度为 的
softmax。
我们发现,一般来说,在第二个目标函数上使用较低的权重可以获得最佳结果。由于软目标产生的梯度的大小为 ,因此在使用硬目标和软目标时,必须将它们乘以 。这可以确保在试验元参数时,如果改变蒸馏所用的温度,硬目标和软目标的相对贡献大致保持不变。