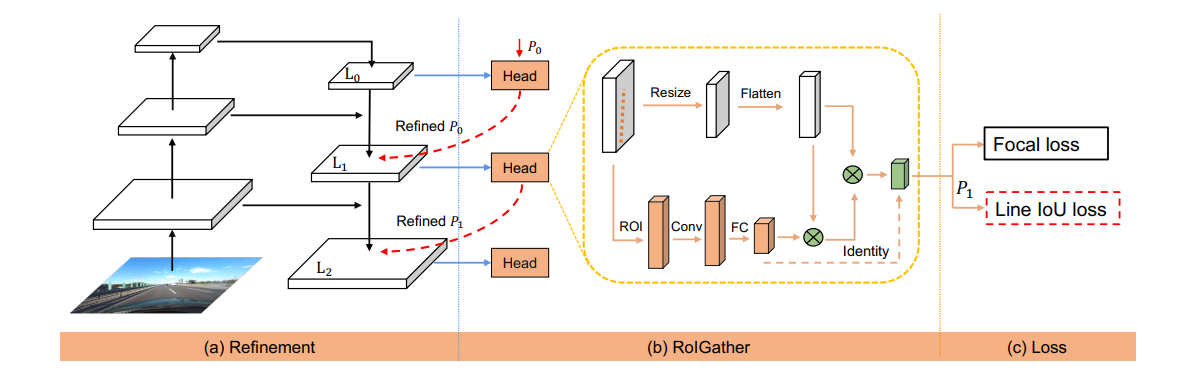
介绍
我们介绍了Bootstrap Your Own Latent(BYOL),这是一种自我监督的图像表征学习的新方法。
从一个图像的增强视图中,BYOL训练其online网络来预测target网络对同一图像的另一个增强视图的表示。
同时,我们用online网络的慢速动量的平均值来更新目标网络。
BYOL在没有negative pairs的情况下实现了新SOTA,且更具有鲁棒性。
背景
直接在表征空间中进行预测可能会导致表征的坍塌:例如,一个在不同视图中不变的表征总是完全预测自己。 对比法通过将预测问题重新表述为辨别问题来规避这一问题:从一个增强视图的表征中,他们学会辨别同一图像的另一个增强视图的表征,以及不同图像的增强视图的表征。然而,这种判别方法通常需要将增强后的视图的每个表现与许多负面的例子进行比较,以找到足够接近的例子,使判别任务具有挑战性。因此,我们的任务是找出这些负面的样本是否是防止坍塌同时保持高性能所不可或缺的。
一个简单的解决方案是使用一个固定的随机初始化网络来生成我们预测的目标。虽然避免了崩溃,但从实验上上看,它并不能产生很好的表征。尽管如此,值得注意的是,使用此过程获得的表示已经比初始固定表示好得多。
这一实验性发现是BYOL的核心动机:从一个给定的表征(被称为target)中,我们可以通过预测目标表征来训练一个新的、可能增强的表征(被称为online)。从此,我们可以期待通过迭代这一程序建立一连串质量不断提高的表征,将随后的online网络作为新的target网络进行进一步训练。
方法

BYOL的目标是学习一个可以用于下游任务中的表针yθ
online网络由一组权重 θ 定义,由三个阶段组成:编码器 fθ 、投影 gθ 和预测 qθ。
target网络提供回归目标来训练online网络,其参数 ξ 是online参数 θ 的指数动量平均值,更准确地说,给定目标衰减率 τ∈[0,1],在每个培训步骤之后,我们执行以下更新(公式 1):
ξ←τξ+(1−τ)θ
给定一组图像 D ,一个从 D 中均匀采样的图像 x∼D,以及两个图像增强的分布 T 和 T′。BYOL从 x 中产生两个增强的视图 v≜t(x) 和v′≜t′(x),从x中产生两个增强视图 t∼T 和t′∼T′。
从第一个增强的视图v,在线网络输出一个表示yθ≜fθ(v)和一个投影 zθ≜gθ(y)。
target网络输出 yξ′≜fξ(v′) 和target投影 zξ′≜gξ(y′) ,来自第二个增强的视图 v′。然后我们输出对 zθ′ 的预测 qxi(zξ),并对 qθ(zθ) 和 zξ′ 进行 l 正则化,使 qθ(zθ)≜qθ(zθ)/∣∣qθ(zθ)∣∣2,zξ′≜zξ′/∣∣zξ′∣∣2。此预测值仅应用于online分支,使 online管道和target管道之间的体系结构不对称.
最后,我们定义了归一化预测和目标预测之间的以下均方误差(公式 2):
Lθ,ξ=≜∣∣qξ−zx′i∣∣22=2−2⋅∣∣qθ(zθ)∣∣2⋅∣∣zξ′∣∣2⟨qθ(zθ),zθ′⟩
我们将公式2中的损失 Lθ,ξ 对称化,分别将 v′ 送入online 网络和 v 送入target网络,计算 Lθ,ξ。
在每个训练步骤中,我们执行一个随机优化步骤,以最小化 Lθ,ξBYOL 只与 θ 有关,而与 ξ 无关,如图2中的停止梯度所描述的。BYOL的动态被总结为:
θ←optimizer(θ,ΔθLθ,ξBYOL,η)
ξ←τξ+(1−τ)θ
其中 η 是学习率。
实现细节
图像增强:BYOL使用与SimCLR相同的一套图像增强方法。首先,选择一个随机的图像patch,将其大小调整为224×224,并随机进行水平翻转,然后进行颜色变形,包括亮度、对比度、饱和度、色调调整的随机序列,以及可选的灰度转换。 最后,高斯模糊和日照化被应用到patch上。
架构:我们使用ResNet 作为解码器 fθ 和 fξ。表征 y 对应于最终平均池化层的输出,其特征维度为2048(宽度乘数为 1×)。表征 y 被多层感知器(MLP) gθ 投影到一个较小的空间,同样,target投影 gξ 也是如此。这个MLP包括一个输出大小为 4096 的线性层,批量归一化,ReLU,以及最后一个输出尺寸为256的线性层。
优化器:我们使用LARS优化器,使用余弦衰减学习率。基础学习率 0.2 ,与批次大小成线性比例 LearningRate=0.2×BatchSize/256。此外,我们使用 1.5e−6 的全局权重衰减参数,同时排除了LARS适应和权重衰减中的偏差和批量归一化参数。对于target网络,指数动量平均参数τ从τbase=0.996开始,在训练期间增加到1。具体来说,我们将 τ 设定为 1−(1−τbase)−(cos(πk/K)+1)/2 ,其中 k 为当前训练步骤,K为最大训练步骤数。我们使用4096的batch size,分给 512 个云计算TPU v3核。在这种设置下,对于 ResNet-50(×1)的训练时间大约为8小时。